Linear Regression using Graphlab
Fire up graphlab create
import graphlab
Load some house value vs. crime rate data
Dataset is from Philadelphia, PA and includes average house sales price in a number of neighborhoods. The attributes of each neighborhood we have include the crime rate (‘CrimeRate’), miles from Center City (‘MilesPhila’), town name (‘Name’), and county name (‘County’).
sales = graphlab.SFrame.read_csv('Philadelphia_Crime_Rate_noNA.csv/')
------------------------------------------------------
Inferred types from first 100 line(s) of file as
column_type_hints=[int,float,float,float,float,str,str]
If parsing fails due to incorrect types, you can correct
the inferred type list above and pass it to read_csv in
the column_type_hints argument
------------------------------------------------------
sales
Exploring the data
The house price in a town is correlated with the crime rate of that town. Low crime towns tend to be associated with higher house prices and vice versa.
graphlab.canvas.set_target('ipynb')
sales.show(view="Scatter Plot", x="CrimeRate", y="HousePrice")
Fit the regression model using crime as the feature
crime_model = graphlab.linear_regression.create(sales, target='HousePrice', features=['CrimeRate'],validation_set=None,verbose=False)
Let’s see what our fit looks like
Matplotlib is a Python plotting library that is also useful for plotting. You can install it with:
‘pip install matplotlib’
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(sales['CrimeRate'],sales['HousePrice'],'.',
sales['CrimeRate'],crime_model.predict(sales),'-')
[<matplotlib.lines.Line2D at 0x118f2d150>,
<matplotlib.lines.Line2D at 0x118f2d390>]
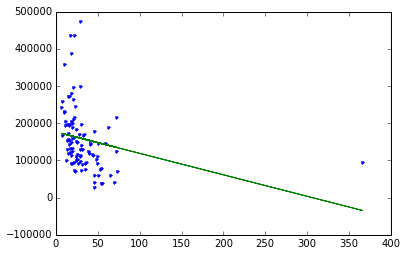
Above: blue dots are original data, green line is the fit from the simple regression.
Remove Center City and redo the analysis
Center City is the one observation with an extremely high crime rate, yet house prices are not very low. This point does not follow the trend of the rest of the data very well. A question is how much including Center City is influencing our fit on the other datapoints. Let’s remove this datapoint and see what happens.
sales_noCC = sales[sales['MilesPhila'] != 0.0]
sales_noCC.show(view="Scatter Plot", x="CrimeRate", y="HousePrice")
Refit our simple regression model on this modified dataset:
crime_model_noCC = graphlab.linear_regression.create(sales_noCC, target='HousePrice', features=['CrimeRate'],validation_set=None, verbose=False)
Look at the fit:
plt.plot(sales_noCC['CrimeRate'],sales_noCC['HousePrice'],'.',
sales_noCC['CrimeRate'],crime_model.predict(sales_noCC),'-')
[<matplotlib.lines.Line2D at 0x1172d8050>,
<matplotlib.lines.Line2D at 0x1172d8290>]
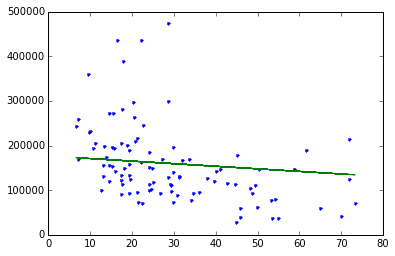
Compare coefficients for full-data fit versus no-Center-City fit
Visually, the fit seems different, but let’s quantify this by examining the estimated coefficients of our original fit and that of the modified dataset with Center City removed.
crime_model.get('coefficients')
crime_model_noCC.get('coefficients')
Above: We see that for the “no Center City” version, per unit increase in crime, the predicted decrease in house prices is 2,287. In contrast, for the original dataset, the drop is only 576 per unit increase in crime. This is significantly different!
High leverage points:
Center City is said to be a “high leverage” point because it is at an extreme x value where there are not other observations. As a result, recalling the closed-form solution for simple regression, this point has the potential to dramatically change the least squares line since the center of x mass is heavily influenced by this one point and the least squares line will try to fit close to that outlying (in x) point. If a high leverage point follows the trend of the other data, this might not have much effect. On the other hand, if this point somehow differs, it can be strongly influential in the resulting fit.
Influential observations:
An influential observation is one where the removal of the point significantly changes the fit. As discussed above, high leverage points are good candidates for being influential observations, but need not be. Other observations that are not leverage points can also be influential observations (e.g., strongly outlying in y even if x is a typical value).
Remove high-value outlier neighborhoods and redo analysis
Based on the discussion above, a question is whether the outlying high-value towns are strongly influencing the fit. Let’s remove them and see what happens.
sales_nohighend = sales_noCC[sales_noCC['HousePrice'] < 350000]
crime_model_nohighend = graphlab.linear_regression.create(sales_nohighend, target='HousePrice', features=['CrimeRate'],validation_set=None, verbose=False)
Do the coefficients change much?
crime_model_noCC.get('coefficients')
crime_model_nohighend.get('coefficients')
Above: We see that removing the outlying high-value neighborhoods has some effect on the fit, but not nearly as much as our high-leverage Center City datapoint.