Softmax分类
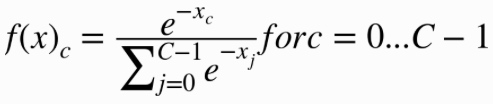
示例
数据集来自https://archive.ics.uci.edu/ml/datasets/Iris,包含4个feature和3个分类:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class: – Iris Setosa – Iris Versicolour – Iris Virginica
#!/usr/bin/env python
import os
import tensorflow as tf
# initialize variables/model parameters
W = tf.Variable(tf.zeros([4, 3]), name="weights")
b = tf.Variable(tf.zeros([3]), name="bias")
def read_csv(batch_size, file_name, record_defaults):
full_path = os.path.dirname(os.path.realpath(__file__)) + "/" + file_name
filename_queue = tf.train.string_input_producer([full_path])
reader = tf.TextLineReader(skip_header_lines=1)
key, value = reader.read(filename_queue)
# decode_csv will convert a Tensor from type string (the text line) in
# a tuple of tensor columns with the specified defaults, which also
# sets the data type for each column
decoded = tf.decode_csv(value, record_defaults=record_defaults)
# batch actually reads the file and loads "batch_size" rows in a single
# tensor
return tf.train.shuffle_batch(decoded,
batch_size=batch_size,
capacity=batch_size * 50,
min_after_dequeue=batch_size)
def inference(X):
# compute inference model over data X and return the result
return tf.nn.softmax(tf.matmul(X, W) + b)
def loss(X, Y):
# compute loss over training data X and expected outputs Y
return tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
tf.matmul(X, W) + b, Y))
def inputs():
sepal_length, sepal_width, petal_length, petal_width, label =\
read_csv(100, "iris.data", [[0.0], [0.0], [0.0], [0.0], [""]])
# convert class names to a 0 based class index.
label_number = tf.to_int32(tf.argmax(tf.to_int32(tf.pack([
tf.equal(label, ["Iris-setosa"]),
tf.equal(label, ["Iris-versicolor"]),
tf.equal(label, ["Iris-virginica"])
])), 0))
# Pack all the features that we care about in a single matrix;
# We then transpose to have a matrix with one example per row and one
# feature per column.
features = tf.transpose(
tf.pack([sepal_length, sepal_width, petal_length, petal_width]))
return features, label_number
def train(total_loss):
# train / adjust model parameters according to computed total loss
learning_rate = 0.01
return tf.train.GradientDescentOptimizer(learning_rate).minimize(
total_loss)
def evaluate(sess, X, Y):
# evaluate the resulting trained model
predicted = tf.cast(tf.arg_max(inference(X), 1), tf.int32)
return sess.run(tf.reduce_mean(tf.cast(tf.equal(predicted, Y),
tf.float32)))
# Create a saver.
# saver = tf.train.Saver()
# Launch the graph in a session, setup boilerplate
with tf.Session() as sess:
tf.initialize_all_variables().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
#coord = tf.train.Coordinator()
#threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# actual training loop
training_steps = 1000
for step in range(training_steps):
sess.run([train_op])
# for debugging and learning purposes, see how the loss gets decremented
# through training steps
if step % 10 == 0:
print "loss at step ", step, ":", sess.run([total_loss])
# save training checkpoints in case loosing them
# if step % 1000 == 0:
# saver.save(sess, 'my-model', global_step=step)
print evaluate(sess, X, Y)
# coord.request_stop()
# coord.join(threads)
# saver.save(sess, 'my-model', global_step=training_steps)