Embeddings
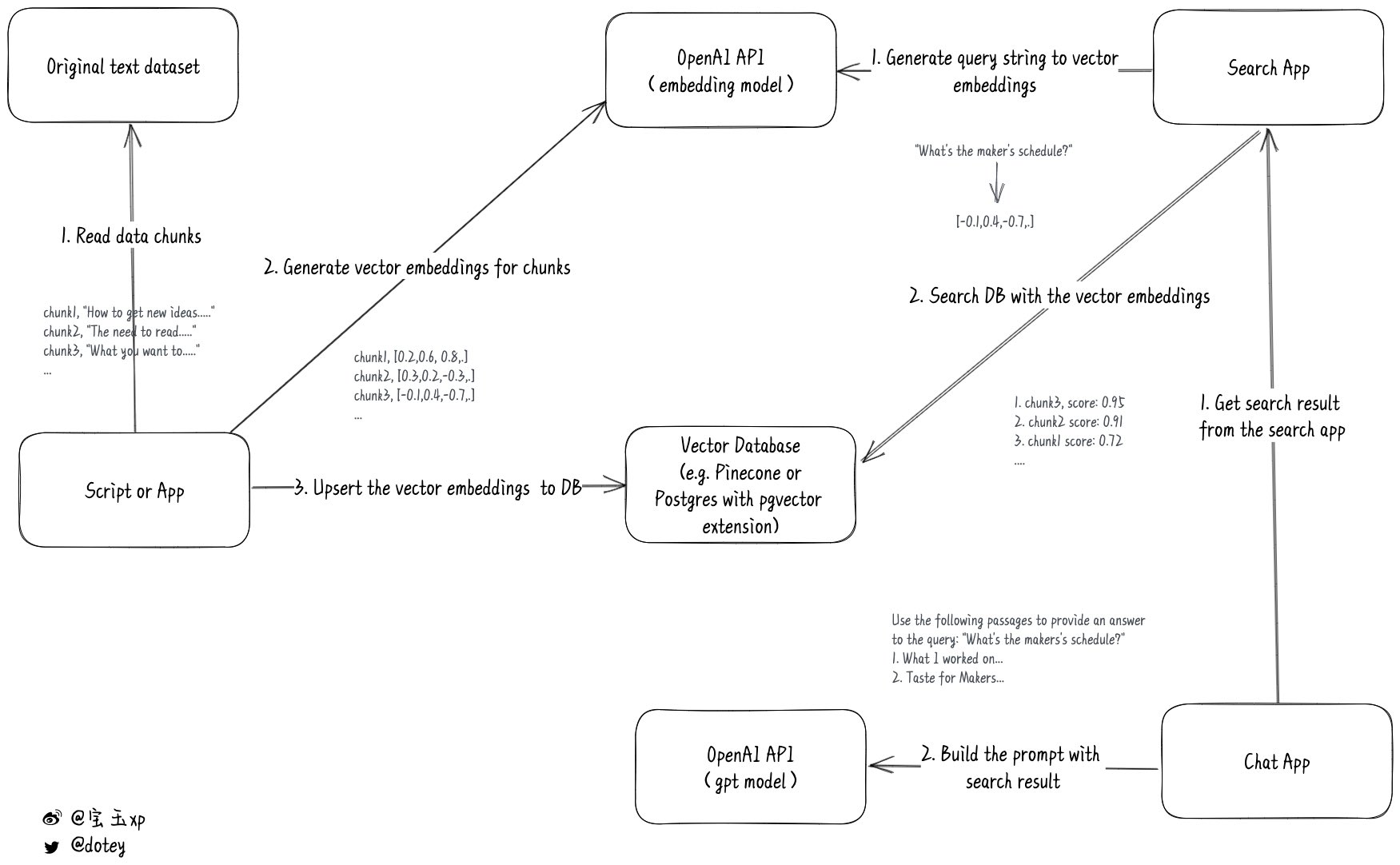
ChatGPT 允许的最大 token 数为 4096(对应模型 gpt-3.5-turbo),会话内容超过 4096 时,要么截断内容,要么借助 embeddings 在本地构建好上下文信息之后再合并到 Prompts 一起发送给 OpenAI ChatGPT API。比如,Paul Graham GPT 就使用后一种方法让你可以和保罗·格雷厄姆(Paul Graham)的所有论文进行聊天。这种方法的详细步骤如下图所示:
(图片来自 Twitter)
- 把原始资料按不超过 8191 token 的大小分块,然后调用 OpenAI embeddings API 将其转换成数字向量,并把结果保存到数据库中。
- 调用 OpenAI embeddings API 把查询消息转换成数字向量,然后到数据库中搜索最相关的上下文信息。
- 合并查询消息和上下文信息,构造新的 Prompts 之后再去调用 OpenAI ChatGPT API,这样就可以获取更好的结果。
这些步骤可以借助 llama-index 实现(注意先设置好环境变量 OPENAI_API_KEY):
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader
from llama_index.langchain_helpers.chatgpt import ChatGPTLLMPredictor
# Load Documents
documents = SimpleDirectoryReader('./data').load_data()
# Create Embeddings Index
llm_predictor = ChatGPTLLMPredictor()
index = GPTSimpleVectorIndex(documents, llm_predictor=llm_predictor)
index.save_to_disk('./index/gpt_index.json')
# The index could be loaded from disk later
# index = GPTSimpleVectorIndex.load_from_disk('index.json')
# Query Index
response = index.query("What did the author do growing up?", llm_predictor=llm_predictor)
print(response)