dropout
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
dropout是CNN中防止过拟合提高效果的一个大杀器. Hintion的直观解释和理由如下:
1. 由于每次用输入网络的样本进行权值更新时,隐含节点都是以一定概率随机出现,因此不能保证每2个隐含节点每次都同时出现,这样权值的更新不再依赖于有固定关系隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。
2. 可以将dropout看作是模型平均的一种。对于每次输入到网络中的样本(可能是一个样本,也可能是一个batch的样本),其对应的网络结构都是不同的,但所有的这些不同的网络结构又同时share隐含节点的权值。这样不同的样本就对应不同的模型,是bagging的一种极端情况。个人感觉这个解释稍微靠谱些,和bagging,boosting理论有点像,但又不完全相同。
3. native bayes是dropout的一个特例。Native bayes有个错误的前提,即假设各个特征之间相互独立,这样在训练样本比较少的情况下,单独对每个特征进行学习,测试时将所有的特征都相乘,且在实际应用时效果还不错。而Droput每次不是训练一个特征,而是一部分隐含层特征。
4. 还有一个比较有意思的解释是,Dropout类似于性别在生物进化中的角色,物种为了使适应不断变化的环境,性别的出现有效的阻止了过拟合,即避免环境改变时物种可能面临的灭亡。
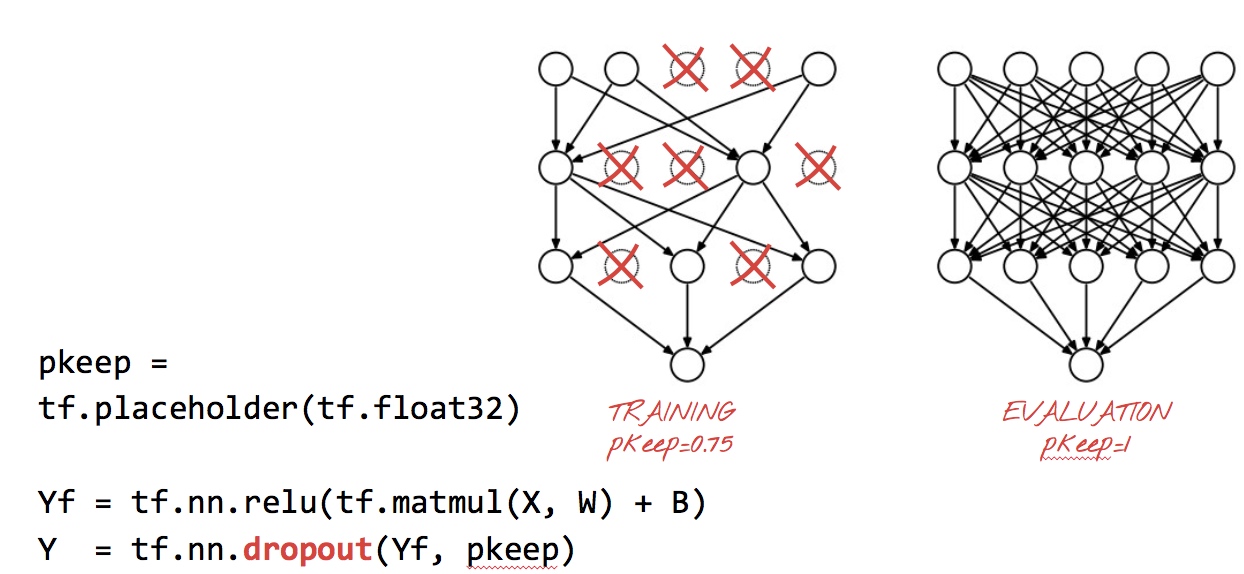
dropout率的选择
- 经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,原因是0.5的时候dropout随机生成的网络结构最多。
- dropout也可以被用作一种添加噪声的方法,直接对input进行操作。输入层设为更接近1的数。使得输入变化不会太大(0.8)