Controller Manager
Controller Manager 由 kube-controller-manager 和 cloud-controller-manager 组成,是 Kubernetes 的大脑,它通过 apiserver 监控整个集群的状态,并确保集群处于预期的工作状态。
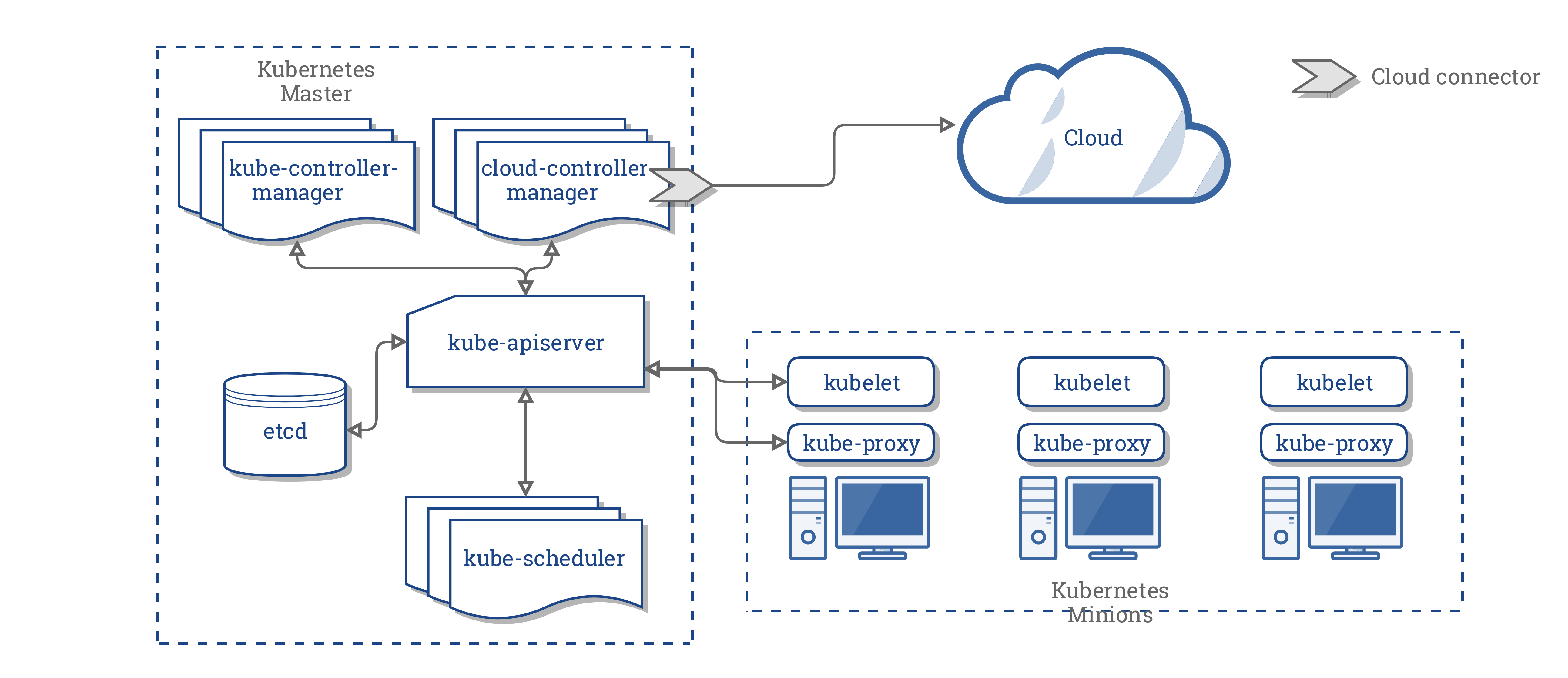
kube-controller-manager 由一系列的控制器组成
- Replication Controller
- Node Controller
- CronJob Controller
- Daemon Controller
- Deployment Controller
- Endpoint Controller
- Garbage Collector
- Namespace Controller
- Job Controller
- Pod AutoScaler
- RelicaSet
- Service Controller
- ServiceAccount Controller
- StatefulSet Controller
- Volume Controller
- Resource quota Controller
cloud-controller-manager 在 Kubernetes 启用 Cloud Provider 的时候才需要,用来配合云服务提供商的控制,也包括一系列的控制器,如
- Node Controller
- Route Controller
- Service Controller
从 v1.6 开始,cloud provider 已经经历了几次重大重构,以便在不修改 Kubernetes 核心代码的同时构建自定义的云服务商支持。参考 这里 查看如何为云提供商构建新的 Cloud Provider。
Metrics
Controller manager metrics 提供了控制器内部逻辑的性能度量,如 Go 语言运行时度量、etcd 请求延时、云服务商 API 请求延时、云存储请求延时等。Controller manager metrics 默认监听在 kube-controller-manager 的 10252 端口,提供 Prometheus 格式的性能度量数据,可以通过 http://localhost:10252/metrics 来访问。
$ curl http://localhost:10252/metrics
...
# HELP etcd_request_cache_add_latencies_summary Latency in microseconds of adding an object to etcd cache
# TYPE etcd_request_cache_add_latencies_summary summary
etcd_request_cache_add_latencies_summary{quantile="0.5"} NaN
etcd_request_cache_add_latencies_summary{quantile="0.9"} NaN
etcd_request_cache_add_latencies_summary{quantile="0.99"} NaN
etcd_request_cache_add_latencies_summary_sum 0
etcd_request_cache_add_latencies_summary_count 0
# HELP etcd_request_cache_get_latencies_summary Latency in microseconds of getting an object from etcd cache
# TYPE etcd_request_cache_get_latencies_summary summary
etcd_request_cache_get_latencies_summary{quantile="0.5"} NaN
etcd_request_cache_get_latencies_summary{quantile="0.9"} NaN
etcd_request_cache_get_latencies_summary{quantile="0.99"} NaN
etcd_request_cache_get_latencies_summary_sum 0
etcd_request_cache_get_latencies_summary_count 0
...
kube-controller-manager 启动示例
kube-controller-manager \
--enable-dynamic-provisioning=true \
--feature-gates=AllAlpha=true \
--horizontal-pod-autoscaler-sync-period=10s \
--horizontal-pod-autoscaler-use-rest-clients=true \
--node-monitor-grace-period=10s \
--address=127.0.0.1 \
--leader-elect=true \
--kubeconfig=/etc/kubernetes/controller-manager.conf \
--cluster-signing-key-file=/etc/kubernetes/pki/ca.key \
--use-service-account-credentials=true \
--controllers=*,bootstrapsigner,tokencleaner \
--root-ca-file=/etc/kubernetes/pki/ca.crt \
--service-account-private-key-file=/etc/kubernetes/pki/sa.key \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt \
--allocate-node-cidrs=true \
--cluster-cidr=10.244.0.0/16 \
--node-cidr-mask-size=24
控制器
kube-controller-manager
kube-controller-manager 由一系列的控制器组成,这些控制器可以划分为三组
- 必须启动的控制器
- EndpointController
- ReplicationController
- PodGCController
- ResourceQuotaController
- NamespaceController
- ServiceAccountController
- GarbageCollectorController
- DaemonSetController
- JobController
- DeploymentController
- ReplicaSetController
- HPAController
- DisruptionController
- StatefulSetController
- CronJobController
- CSRSigningController
- CSRApprovingController
- TTLController
- 默认启动的可选控制器,可通过选项设置是否开启
- TokenController
- NodeController
- ServiceController
- RouteController
- PVBinderController
- AttachDetachController
- 默认禁止的可选控制器,可通过选项设置是否开启
- BootstrapSignerController
- TokenCleanerController
cloud-controller-manager
cloud-controller-manager 在 Kubernetes 启用 Cloud Provider 的时候才需要,用来配合云服务提供商的控制,也包括一系列的控制器
- CloudNodeController
- RouteController
- ServiceController
高可用
在启动时设置 --leader-elect=true 后,controller manager 会使用多节点选主的方式选择主节点。只有主节点才会调用 StartControllers() 启动所有控制器,而其他从节点则仅执行选主算法。
多节点选主的实现方法见 leaderelection.go。它实现了两种资源锁(Endpoint 或 ConfigMap,kube-controller-manager 和 cloud-controller-manager 都使用 Endpoint 锁),通过更新资源的 Annotation(control-plane.alpha.kubernetes.io/leader),来确定主从关系。
高性能
从 Kubernetes 1.7 开始,所有需要监控资源变化情况的调用均推荐使用 Informer。Informer 提供了基于事件通知的只读缓存机制,可以注册资源变化的回调函数,并可以极大减少 API 的调用。
Informer 的使用方法可以参考 这里。
Node Eviction
Node 控制器在节点异常后,会按照默认的速率(--node-eviction-rate=0.1,即每10秒一个节点的速率)进行 Node 的驱逐。Node 控制器按照 Zone 将节点划分为不同的组,再跟进 Zone 的状态进行速率调整:
- Normal:所有节点都 Ready,默认速率驱逐。
- PartialDisruption:即超过33% 的节点 NotReady 的状态。当异常节点比例大于
--unhealthy-zone-threshold=0.55时开始减慢速率:- 小集群(即节点数量小于
--large-cluster-size-threshold=50):停止驱逐 - 大集群,减慢速率为
--secondary-node-eviction-rate=0.01
- 小集群(即节点数量小于
- FullDisruption:所有节点都 NotReady,返回使用默认速率驱逐。但当所有 Zone 都处在 FullDisruption 时,停止驱逐。