上个月的 KubeCon 上,Google Cloud 宣布在实验环境中成功运行了 13 万节点的 GKE 集群。而在更早的 7 月,AWS 也发布了 EKS 正式支持 10 万节点集群的消息。
10 万节点是什么概念?按 AWS 的说法,这意味着一个集群可以容纳 160 万颗 Trainium 芯片,或者 80 万块 NVIDIA GPU。这已经不是普通的“大规模”了,基本相当于把一个小城市的算力都集中到了一起。
云厂商为什么要卷这么大规模的 Kubernetes 集群?因为 AI 公司们真的需要。
AI 算力的狂热竞赛
过去一年,AI 基础设施的规模膨胀得有些疯狂。
xAI 在 2024 年 9 月上线了 Colossus 集群,10 万块 NVIDIA H100 GPU,从一个废弃工厂改造完成只用了 122 天。三个月后又翻倍到 20 万块。这个集群用来训练 Grok 3,马斯克说要做地球上最强的 AI。
Meta 在 2024 年底拥有 35 万块 H100,2025 年 1 月 Zuckerberg 宣布计划年底达到 130 万块 GPU。
Anthropic 的 Project Rainier 在 2025 年 10 月上线,近 50 万颗 Trainium2 芯片专门用于训练 Claude,是之前训练算力的 5 倍以上。
字节跳动的 MegaScale 系统已经能支撑超过 1.2 万块 GPU 的分布式训练,在 12,288 块 GPU 上训练 175B 参数模型的 MFU 达到 55.2%。
DeepSeek 用 1 万块 GPU 的集群训练出了性能惊艳的模型,还把成本控制得很低。
这些数字背后有一个共同的问题。怎么把这么多 GPU 组织起来,让它们高效协同工作?
答案是 Kubernetes。
为什么是 Kubernetes?
OpenAI 从 2016 年就开始用 Kubernetes 管理深度学习基础设施。他们把 K8s 当作批处理调度系统,用自研的 autoscaler 动态扩缩容集群。用他们基础设施负责人 Christopher Berner 的话说,以前一个研究员要把实验扩展到几百块 GPU,可能需要几个月。现在用 Kubernetes,两三天就能跑起来,一两周就能扩到几百块 GPU。
为什么 Kubernetes 成了 AI 基础设施的首选?
把 PyTorch、TensorFlow 加上各种 CUDA 版本打包成容器镜像,不管在哪台机器上跑,环境都一样。K8s 把 GPU、CPU、内存都当成资源来管理,你告诉它“我要 1000 块 GPU 跑这个任务”,它会自动找到合适的机器、分配资源、启动容器。Kubeflow 管理训练流水线,Karpenter 自动扩缩容节点,各种 Operator 对接不同的硬件,这些工具大大降低了运维成本。同一个集群可以跑大规模预训练、小规模微调、在线推理,资源可以灵活调度。
Anthropic Claude、OpenAI GPT-x、Amazon Nova、Google Gemini 等等,这些大模型底层基本都跑在 Kubernetes 上。Google Cloud 的数据显示,过去一年 GKE 上 TPU 和 GPU 的使用量增长了 900%。
为什么要追求单个超大集群?
可能有人会问,10 万节点太大了,拆成 10 个 1 万节点的集群不行吗?
对于一般应用来说确实可以。微服务、Web 应用这些,拆成多个小集群反而更好管理,AWS 也推荐这种“蜂窝架构”。
但 AI 训练不一样。大模型训练需要成千上万的加速器作为一个整体协同工作,彼此之间要低延迟、高带宽通信。拆到不同集群,资源利用率会下降,大的预训练任务和小的微调任务本可以共享同一个资源池,拆成多个集群后每个集群都得预留余量。跨集群调度也太复杂,一个超大训练任务拆到多个集群,谁来协调?故障发现、修复、监控都会变得更麻烦。很多 ML 框架默认在单集群内运行,有全局视图,拆成多集群框架可能需要改造。
AWS 在博客里也提到,像 Anthropic 这样的客户明确需要超大规模单集群,把不同规模的训练任务、微调实验和批量推理放在同一个资源池里,可以最大化利用昂贵的 AI 加速器。
Kubernetes 原生的天花板
问题是,原生 Kubernetes 的设计目标是 5000 个节点。这对绝大多数企业够用了,但对 AI 训练来说,差了一到两个数量级。
瓶颈在哪?
etcd 是最大的瓶颈。etcd 是 K8s 的 “大脑”,所有集群状态都存在这里。它用 Raft 共识算法保证数据一致性,但这也意味着每次写入都要等多数节点确认。集群越大,etcd 压力越大。
调度器忙不过来。K8s 调度器负责决定每个 Pod 跑在哪个节点上。默认是串行处理的,一个 Pod 调度完才处理下一个。10 万节点、几十万个 Pod,调度器就成了独木桥。
API Server 压力大。所有对集群的读写操作都要经过 API Server。节点心跳、Pod 状态更新、控制器的各种操作,在超大集群里每秒要处理几万甚至十几万次请求。
这些瓶颈不是简单加机器就能解决的,需要架构层面的改造。
AWS 的方案:重新发明 etcd
AWS 选择的路线是保留 etcd 的 API,但把底层架构重新实现了一遍。
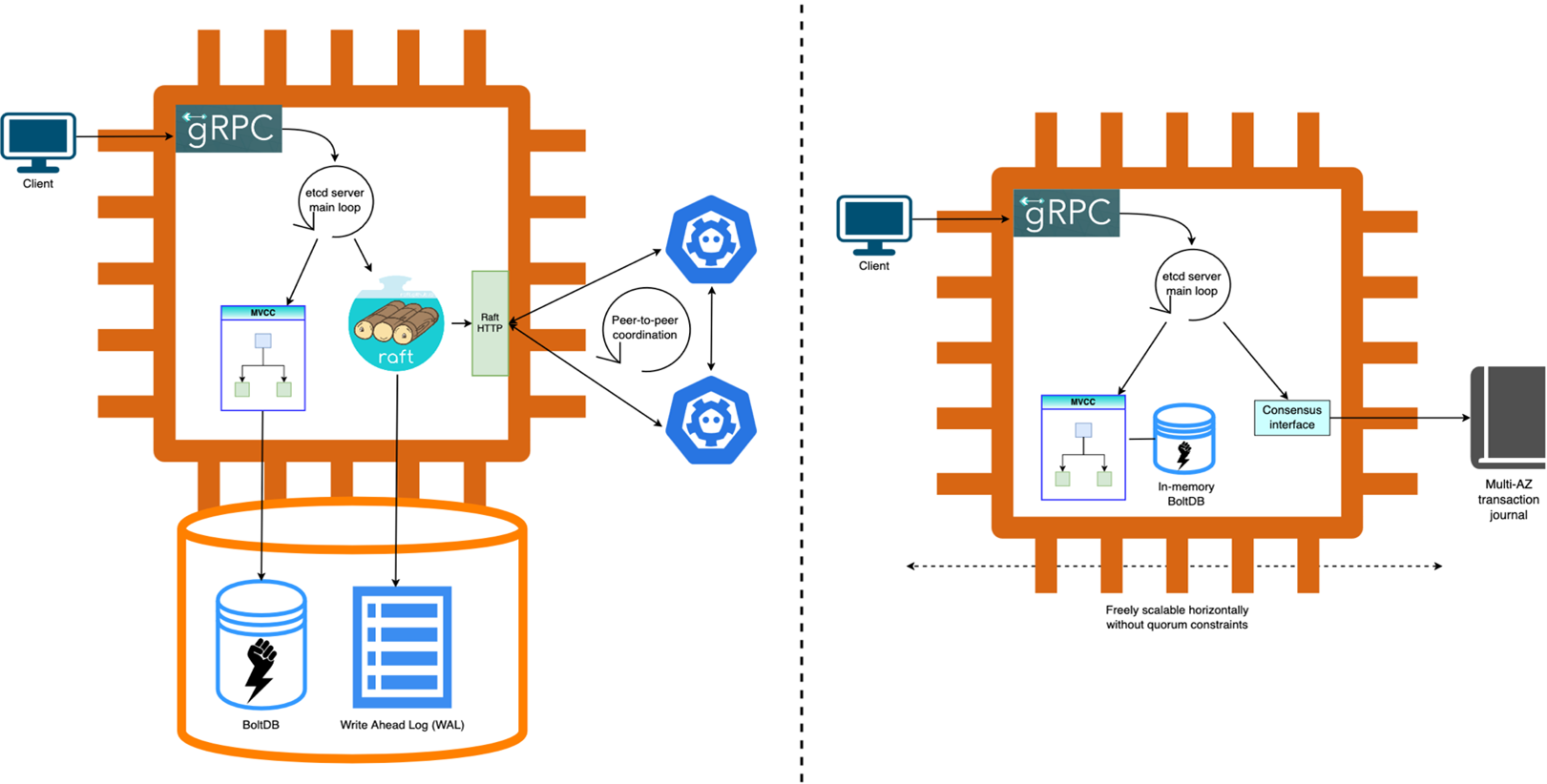
AWS 把 etcd 的 Raft 共识层替换成了内部的 journal 组件。journal 是 AWS 内部用了十多年的东西,专门做跨可用区的高速数据复制。这个改动让 etcd 副本可以自由扩展,不再受 Raft 多数派的限制。
以前 etcd 的数据存在网络挂载的 EBS 磁盘上,现在直接放内存里。因为持久性已经由 journal 保证了,内存里的数据库只是为了快速读取。这个改动带来了数量级的性能提升。
K8s 的不同资源类型不需要跨类型事务。AWS 把 Pod、Node、ConfigMap 等分到不同的 etcd 实例里,写吞吐直接翻了 5 倍。
最终效果怎么样?10 万节点在 50 分钟内全部就绪,每分钟 2000 个节点加入集群。全集群 AMI 升级在 4 小时内完成。etcd 数据库总容量达到 32GB,存储超过 1000 万个 K8s 对象。
Google 的方案:换一个数据库
Google 走了另一条路,直接用 Spanner 替换 etcd。
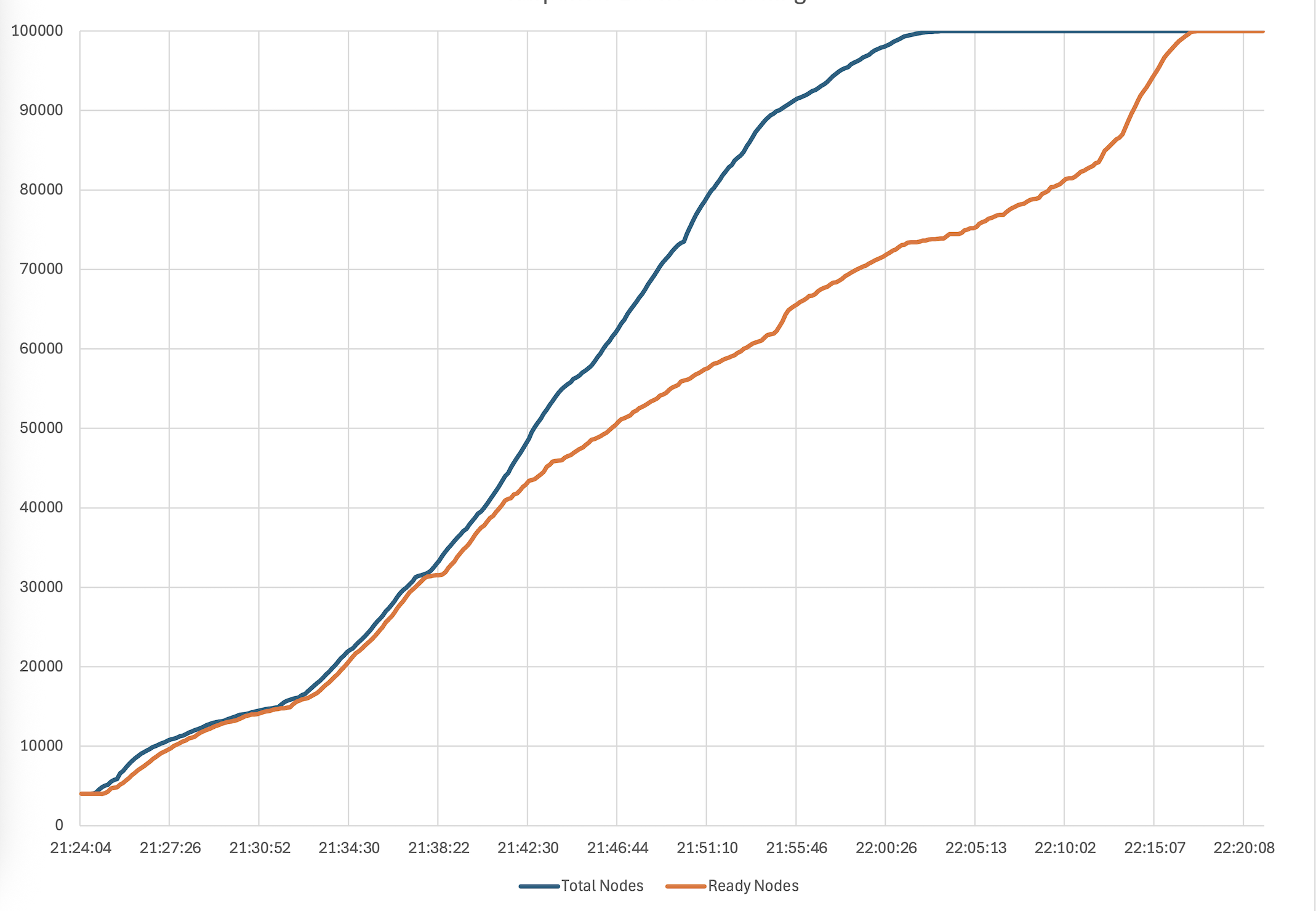
2024 年 11 月,Google 先宣布 GKE 支持 6.5 万节点,可以管理 25 万个 TPU。到了 2025 年 11 月的 KubeCon,他们又展示了 13 万节点的实验结果。
Spanner 是 Google 自研的全球分布式数据库,支撑着 Google 内部无数核心服务。用它来做 K8s 的后端存储,天然就有更好的扩展性。在 13 万节点的测试中,Spanner 每秒处理 1.3 万次 Lease 更新(节点心跳),完全没有瓶颈迹象。Google 认为这套方案还能继续往上扩。
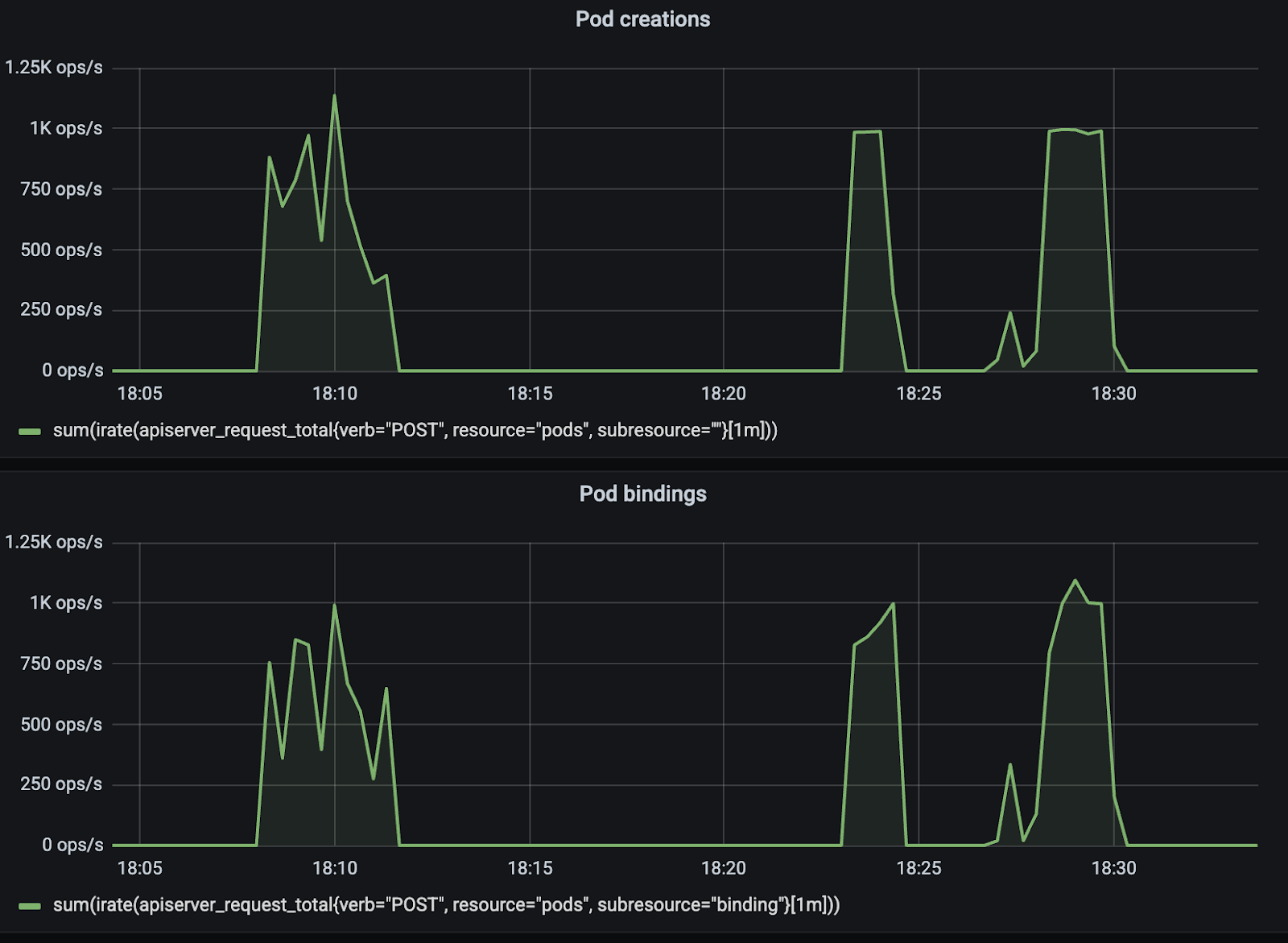
Google 还引入了 Kueue,一个专门为批处理任务设计的作业队列控制器。原生 K8s 调度器是 Pod 级别的,一个一个调度。Kueue 是作业级别的,可以做“全有或全无”的调度,要么整个作业的所有 Pod 都分配到资源,要么一个都不分配。
这对 AI 训练特别重要。一个分布式训练任务需要 1000 个 Pod 同时启动,如果只启动了 999 个,剩下那个分配不到资源,整个任务就卡住了。Kueue 的 Gang Scheduling 能力正好解决这个问题。
最终效果怎么样?13 万个 Pod 在 3 分 40 秒内调度完成。峰值抢占 3.9 万个 Pod 只用了 93 秒。Pod 吞吐稳定在每秒 1000 个。
两条路,殊途同归
AWS 和 Google 的方案看起来不一样,但核心思路是相通的。
**存储层是关键。**原生 etcd 的架构不适合超大规模。不管是改造它还是替换它,都要解决存储层的扩展性问题。
**调度要革新。**单纯的 Pod 级调度不够用,需要作业级别的调度能力。AWS 用 Karpenter 管理节点生命周期,Google 用 Kueue 管理作业队列,都是在原生调度器之上加了一层。
**API 要优化。**减少对后端存储的压力,尽可能从缓存服务请求。两家都在 API Server 层做了大量优化,比如 Kubernetes 1.31 引入的 Consistent Reads from Cache 功能。
**全栈都要改。**不只是控制面,网络、存储、监控都要跟上。AWS 优化了 VPC CNI 的前缀模式,Google 用 GCS FUSE 加速数据访问,两家都做了镜像拉取加速和节点健康自动检测修复。
写在最后
从 5000 节点到 6.5 万、10 万,甚至 13 万节点,Kubernetes 的扩展性边界被一次次推高。背后是 AI 对算力的需求,也是云厂商在基础设施层面的技术竞争。
如果你在自建集群或者混合云环境,这些经验都值得参考。etcd 调优是基本功,但到了一定规模就要考虑架构改造。引入 Kueue 或类似的作业队列,能显著改善批处理任务的调度效率。关注社区的新特性,比如 Gang Scheduling、流式 List 响应等等。
还有一个趋势值得关注,多集群方案。Google 在文章里提到,单个 GPU 功耗越来越高,NVIDIA GB200 需要 2700W,10 万节点集群的电力消耗可能达到数百兆瓦,这已经超过了单个数据中心的供电能力。未来的超大规模 AI 平台可能需要跨数据中心、跨集群的方案。MultiKueue 就是 Google 在这个方向上的探索。
AWS 和 Google 走了不同的技术路线,但都证明了一件事,Kubernetes 的天花板还远没到。只要有足够的工程投入,它可以支撑起 AI 时代最苛刻的算力需求。
相关链接:
- AWS 博客原文:https://aws.amazon.com/blogs/containers/under-the-hood-amazon-eks-ultra-scale-clusters/
- Google Cloud 博客原文:https://cloud.google.com/blog/products/containers-kubernetes/how-we-built-a-130000-node-gke-cluster
欢迎长按下面的二维码关注 Feisky 公众号,了解更多云原生和 AI 知识。
