CNCF 在刚刚举办的 KubeCon NA 发布了最新一期技术雷达报告,这次聚焦三个核心领域:AI 推理工具与引擎、机器学习编排工具,还有最近很火的 Agentic AI 平台与系统。报告基于 300 多位专业开发者在 2025 年第三季度的真实使用体验,给技术选型提供了不少参考。

CNCF 的 CTO Chris Aniszczyk 在报告发布时说:“构建和运营 AI 系统的组织不能再用五年前的方式对待工具选型了。这次调查证实了云原生的可扩展基础设施和编排能力,不只是对后端应用重要,对推理管道和 Agentic AI 系统同样关键。选择被评为“采纳”级别的技术能帮你降低风险,提高生产力。”
报告怎么评级的?
报告把相关的技术分成四个等级:
- **Adopt(采纳)**是那些靠谱且适合大多数场景的技术;
- **Trial(试验)**值得你去试试,看能不能解决自己的问题;
- **Assess(评估)**需要谨慎看看再决定;
- **Hold(暂缓)**现在还不够成熟的。
这些分级主要看两个维度:开发者怎么评价技术的成熟度(稳定性和可靠性)以及实用性(能不能满足项目需求),还会问大家愿不愿意推荐给别人。需要说明的是,这里的评级是开发者自己的感受,跟 CNCF 项目官方的成熟度模型(Sandbox/Incubating/Graduated)不是一回事。
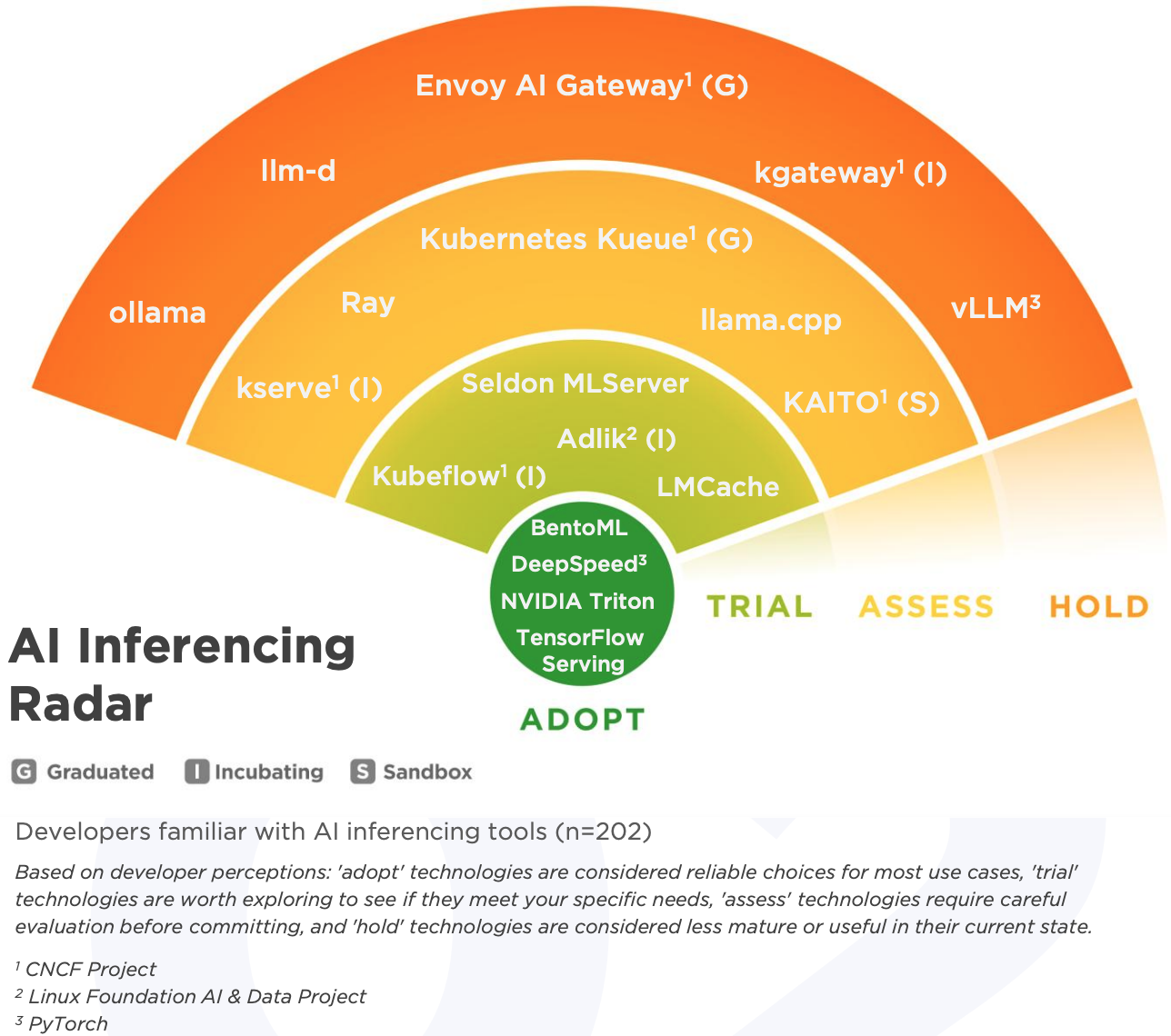
AI 推理工具
在 AI 推理这块,报告一共评估了 20 多个工具。NVIDIA Triton、DeepSpeed、TensorFlow Serving 和 BentoML拿到了采纳级别,算是目前最稳的选择。
成熟度怎么样?
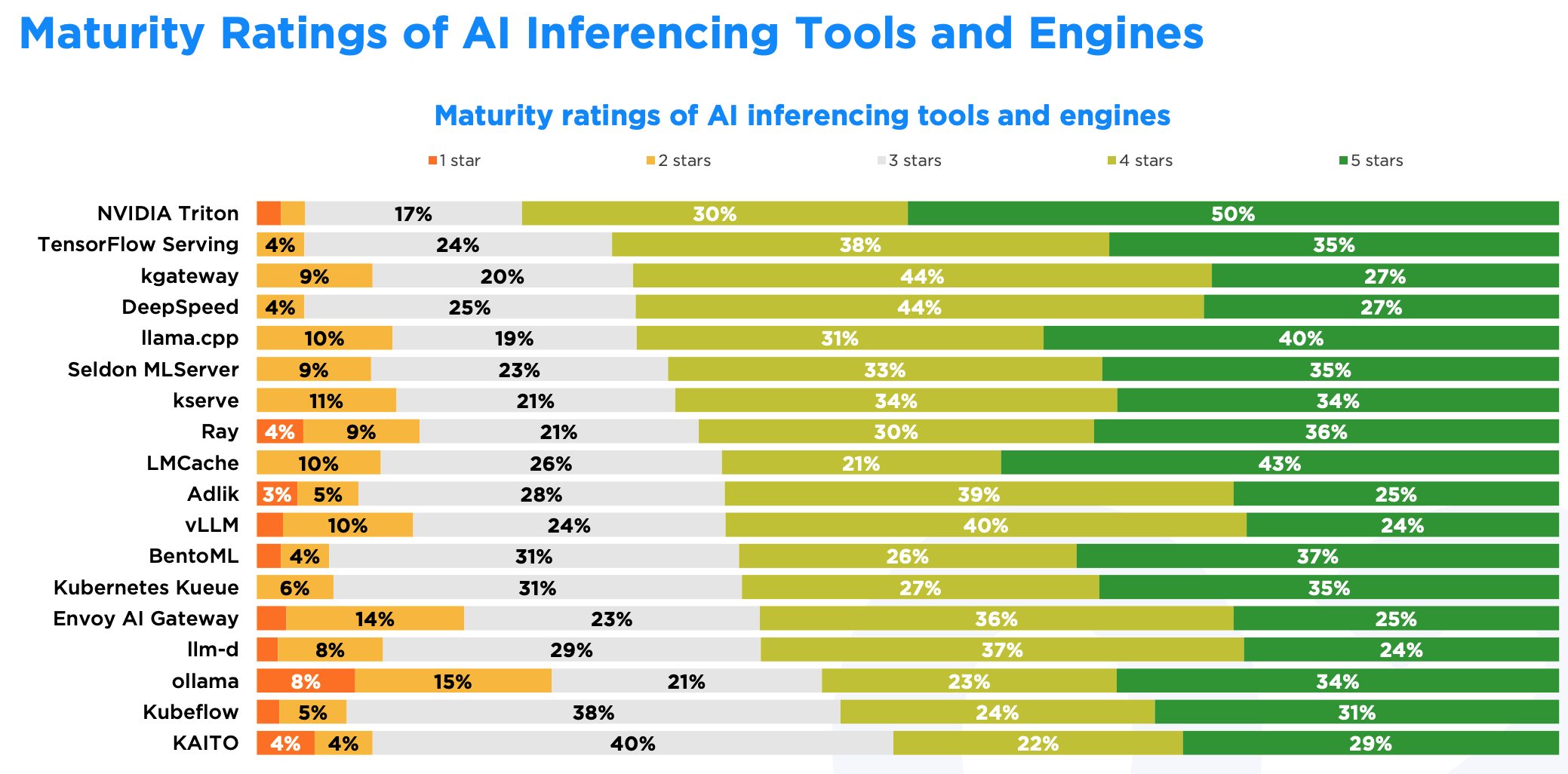
NVIDIA Triton 在成熟度上领先,50% 的用户给了 5 星,另外 30% 给了 4 星。这说明 Triton 在稳定性和可靠性上确实得到了广泛认可。
LMCache 拿到了 43% 的 5 星评价,但 4 星只有 21%。虽然在一部分开发者眼里表现不错,但整体认可度上比 Triton 还有不少差距。
Ollama 就比较两极化了:34% 的 5 星算是中等水平,但同时 23% 的差评也是所有项目里面最高的。这说明接近四分之一的开发者觉得 Ollama 成熟度不够,可能在某些场景下确实不太好用。
此外,TensorFlow Serving、DeepSpeed、kgateway 以及 llama.cpp 虽然 5 星比例不是最高的,但综合正面评价排在前5名,说明它们能满足更多场景的需求。
实用性如何?
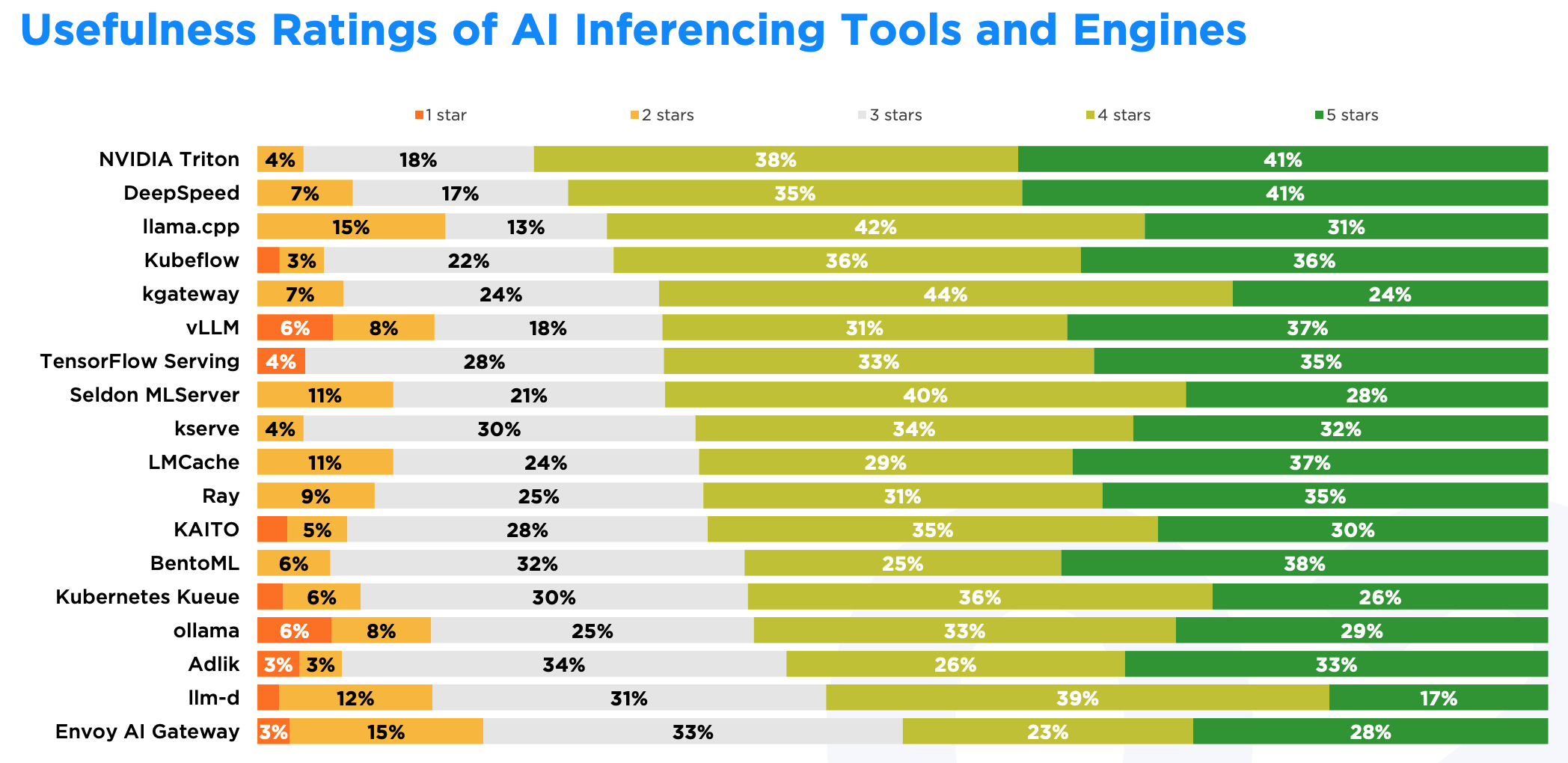
实用性方面,NVIDIA Triton 同样第一名,获得 41% 的 5 星 + 38% 的 4 星。DeepSpeed、llama.cpp 和 Kubeflow 紧随其后。
Envoy AI Gateway 和 llama.cpp 的负面评价比较多,分别是 18% 和 15%。但 llama.cpp 的正面评价比例(73%)远高于 Envoy AI Gateway(51%),说明 Envoy AI Gateway 的实用性还差得多远,而 llama.cpp 的整体实用性还是得到多数人认可的。
推荐意愿
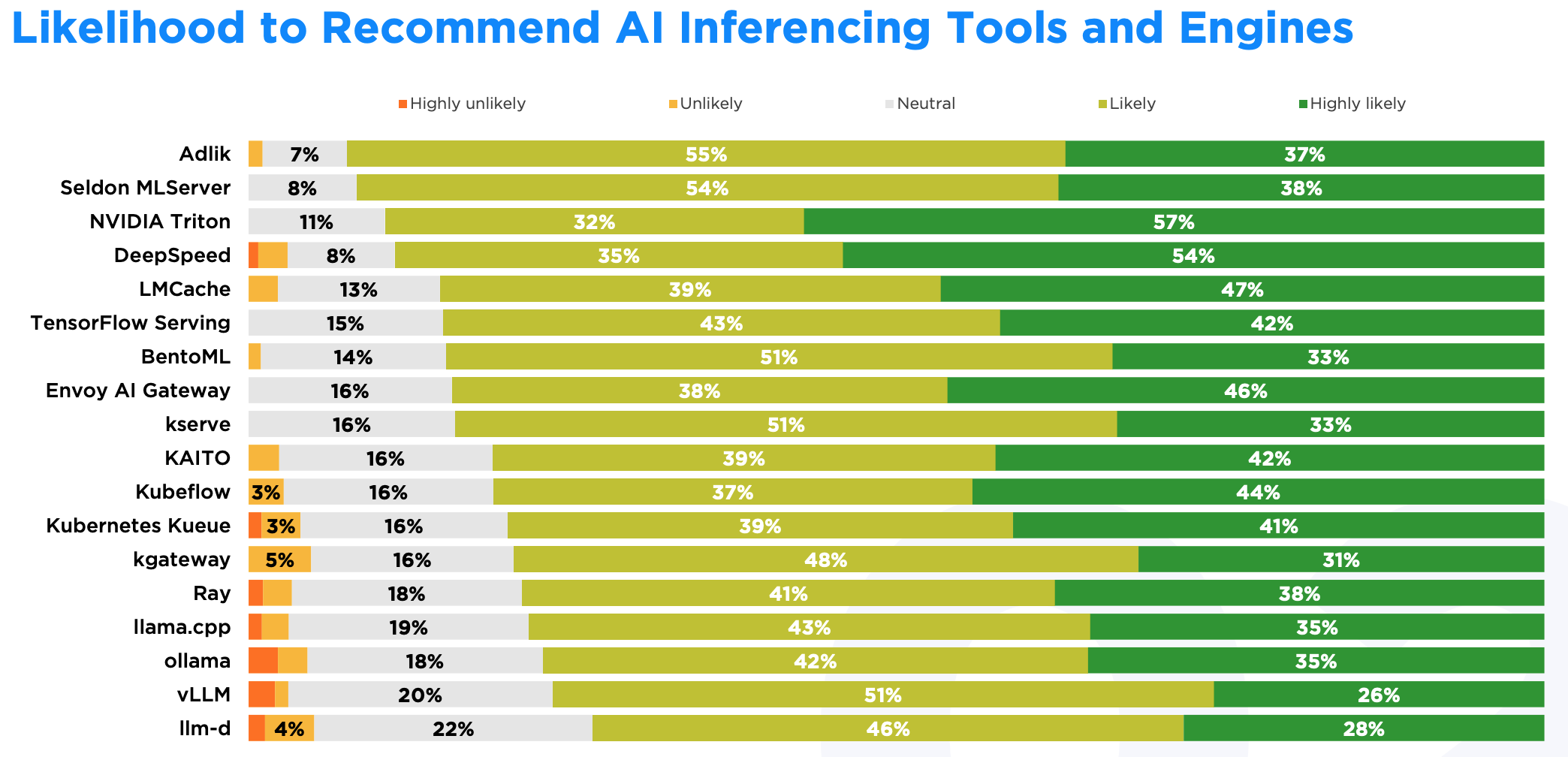
在推荐意愿上,NVIDIA Triton 有 57% 的用户会强烈推荐。但 Adlik 虽然用的人不多,却拿到了 92% 的推荐率,是所有工具里最高的。这个现象挺有意思:那些满足特定企业需求的工具(比如模型优化或者特定硬件部署)即使不是全能选手,也能建立起忠实的用户群。
有意思的是,所有技术的推荐比例都过半,最低的 llm-d 也有 74%。开发者在推荐技术时会考虑不同场景,就算某个工具不符合自己的需求,也可能觉得它在其他地方能派上用场。
机器学习编排
再来看机器学习编排。ML 编排只有两个采纳级别的项目,即 Airflow 和 Metaflow。BentoML 在 AI 推理领域是采纳级别,但在编排领域只是试验级别。这说明一个工具可能在多个领域都不错,但很难在所有领域都成为领头羊。
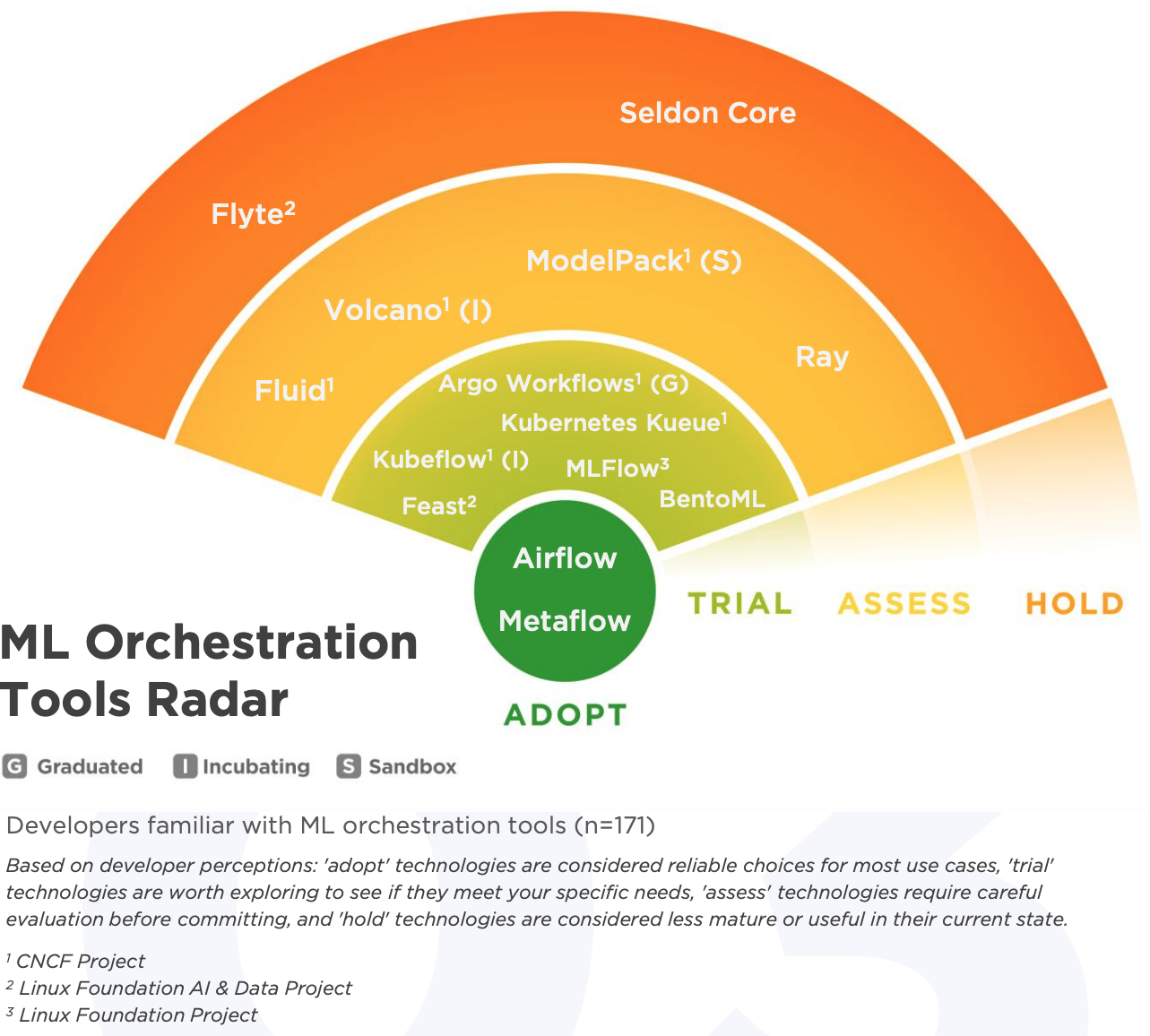
成熟度怎么样?
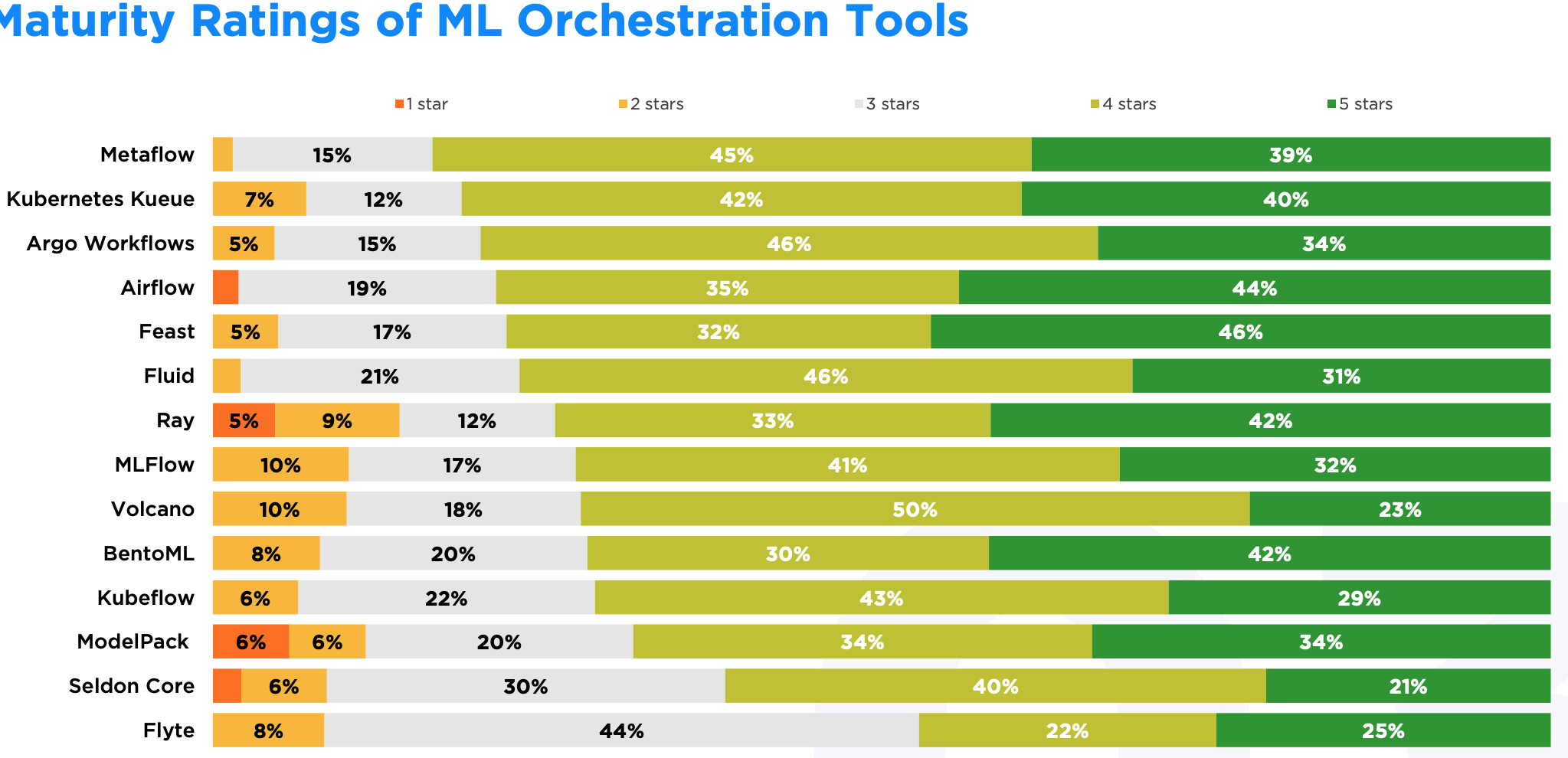
Feast 在 5 星评价比例上表现突出,但如果看 4-5 星的综合比例,Metaflow、Kueue 和 Argo Workflows 更具优势。Feast 的用户基数较小,长期用户也不多,而 Metaflow 和 Argo Workflows 能为更多用户提供稳定的使用体验。
Ray 作为主流公有云厂商都官方支持的项目,综合好评中等,但综合差评倒数第一,倒是挺意外的。
实用性如何?
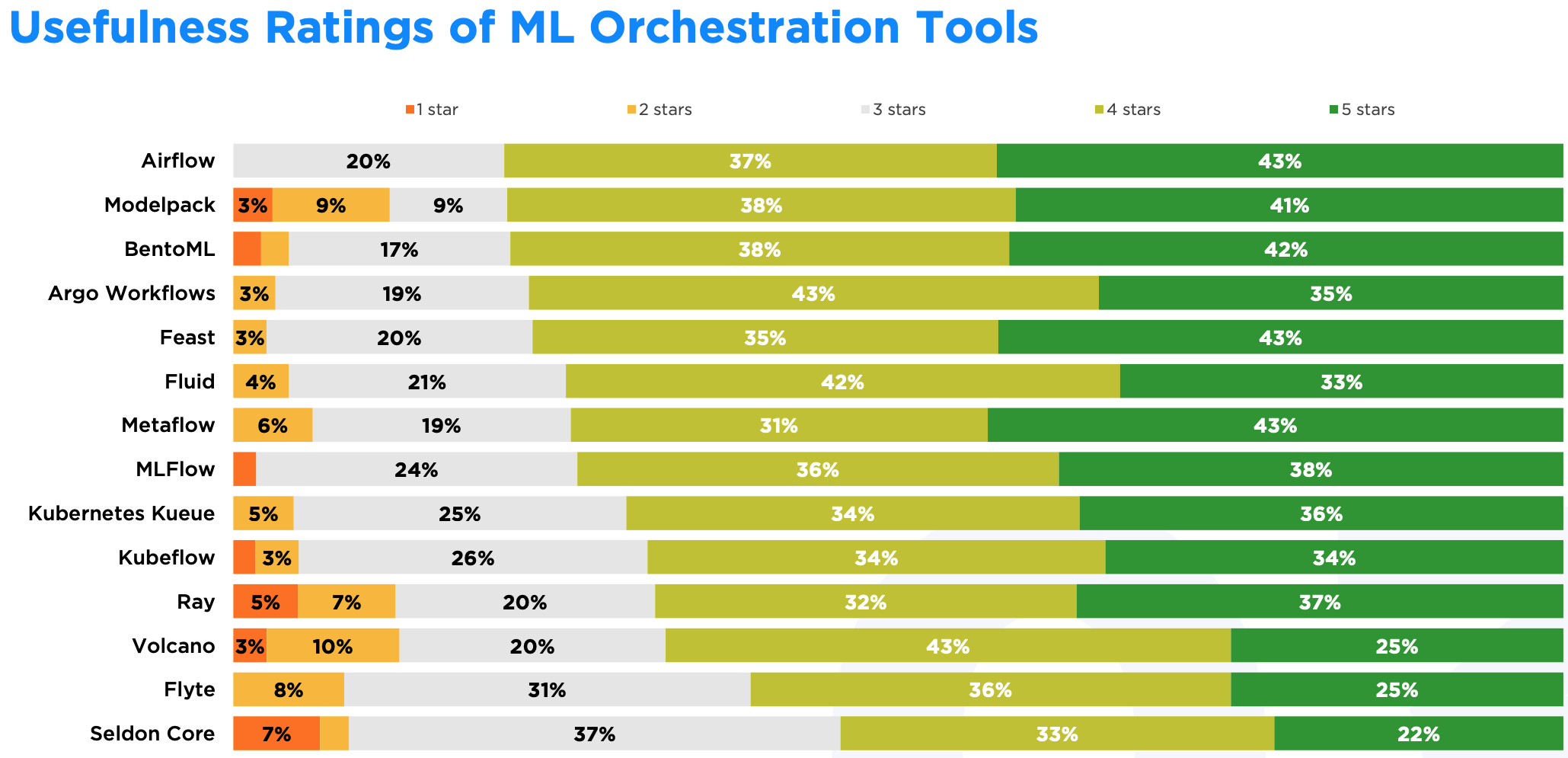
在实用性上,Airflow、Modelpack 和 BentoML 名列综合好评前三,而 Metaflow 则是 5 星好评第一。 其中,Airflow 特别突出,没有 1-2 星的差评,说明在满足项目需求这点上,它得到了大部分用户的认可。
跟成熟度类似,Ray 在实用性上也很差,跟 Volcano 和 Modelpack 并列倒数前三名,在选型时可能要注意避开。
推荐意愿
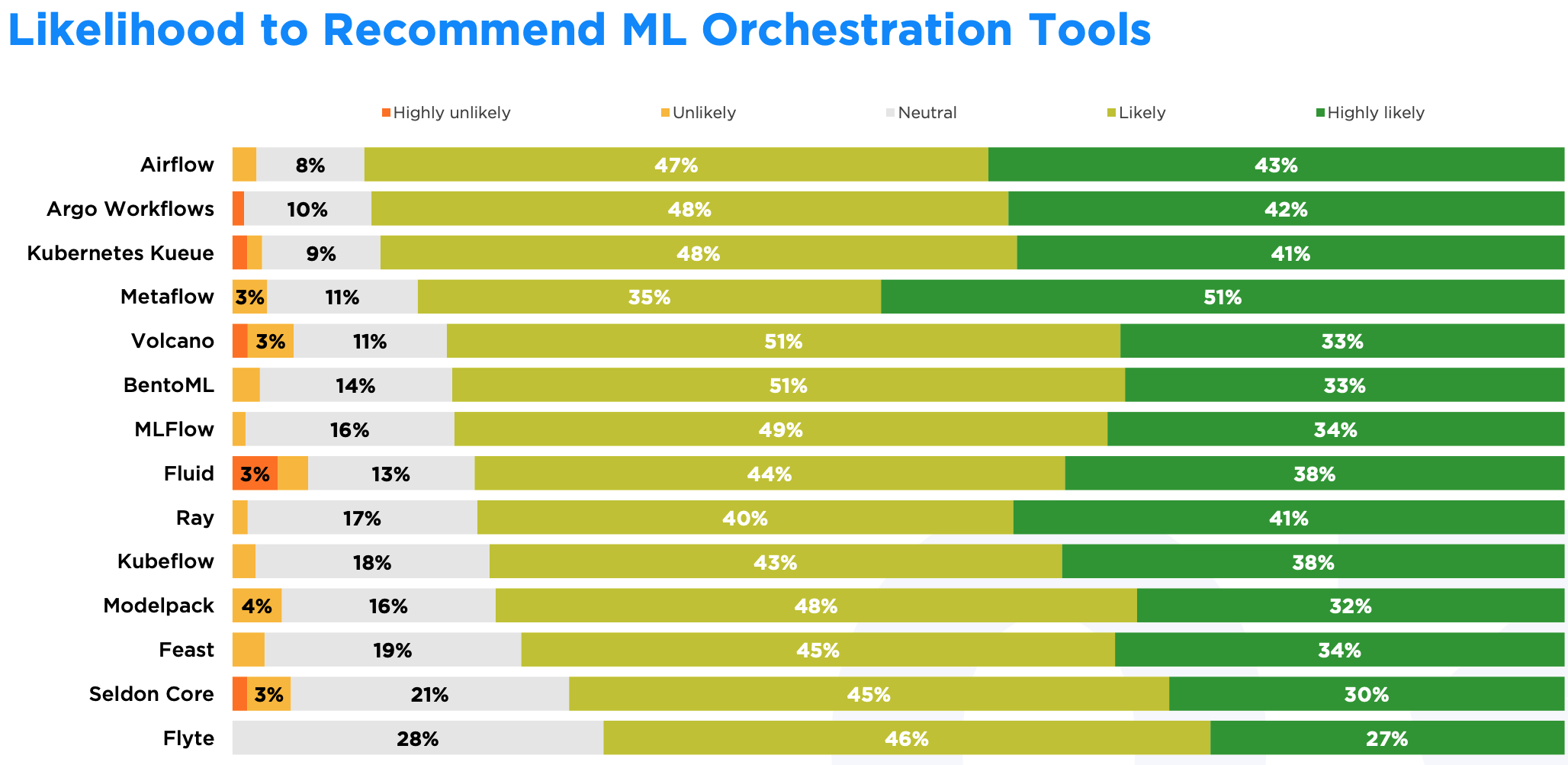
Metaflow 有 51% 的用户会强烈推荐,而 Airflow 和 Argo Workflows 的综合推荐比例都达到了 90%。
BentoML 在成熟度和实用性方面表现良好,84% 的用户愿意推荐,但只有 33% 的用户会强烈推荐。这表明 BentoML 能够满足用户需求,但在开发者工作流程中的核心地位仍有待提升。
SlashData 高级市场研究顾问 Liam Bollmann-Dodd 对这些发现评价道:“这些数据显示,AI/ML 工具链已经非常多样化。Metaflow 和 Airflow 是很好的例子,说明开发者通过稳定性和针对性设计建立了信任。即使是像 Flyte 和 Seldon Core 这样较新的项目,也展现出增长势头,说明仍有差异化发展的机会。”
Agentic AI 平台
Agentic AI 这块,毫无疑问 MCP 已经得到大规模采纳,所有主流的 Agentic AI 工具和平台都已经支持 MCP。此外,Llama Stack 也达到了采纳级别,而 kgateway 和 kagent 这两个 CNCF 项目还在评估级别。
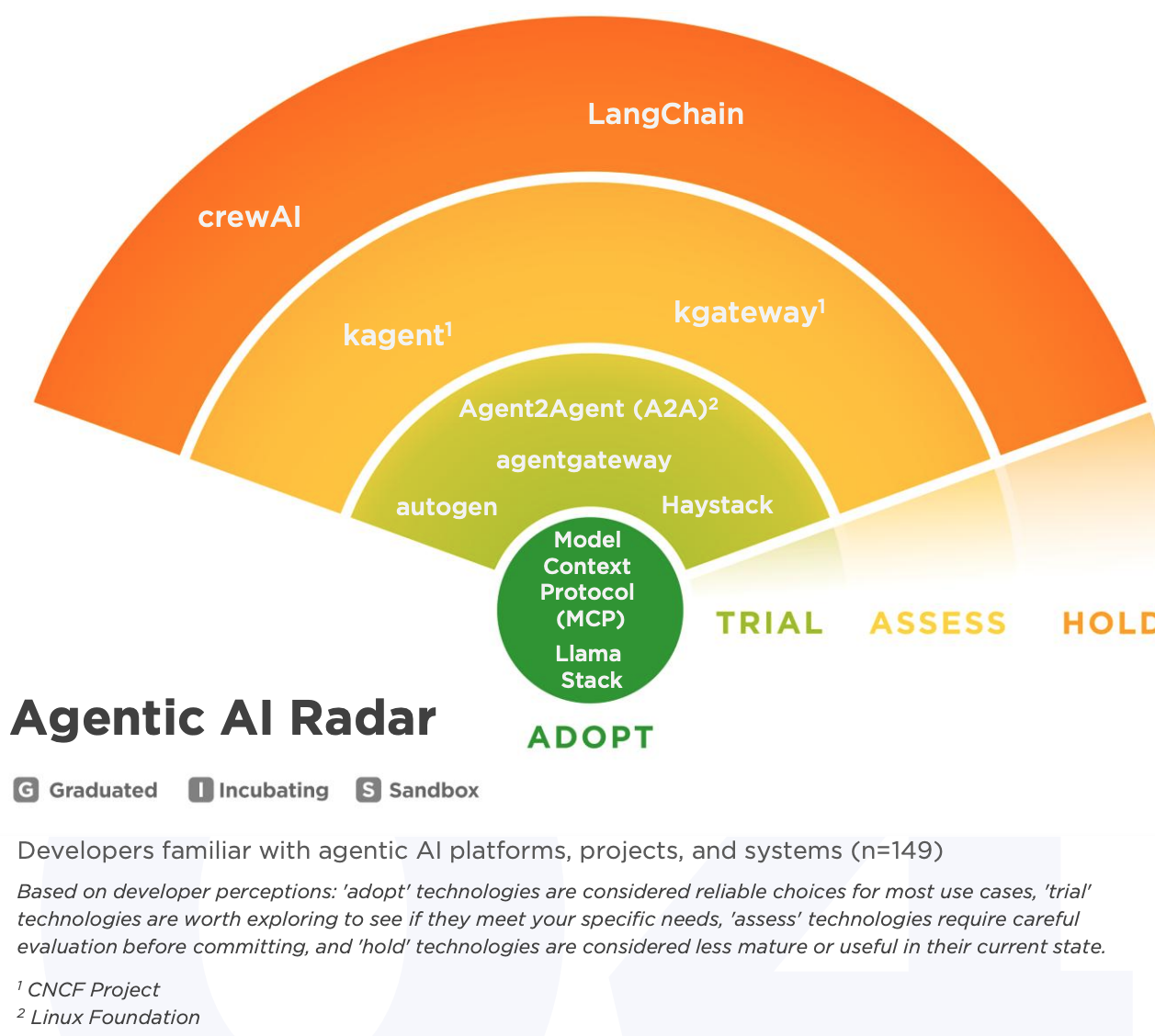
成熟度怎么样?
agentgateway 和 Llama Stack 的 5 星评价比例最高,分别是 38% 和 35%。MCP 虽然 5 星比例是 33%,但 4-5 星综合好评达到 73%,是所有项目里最高的。
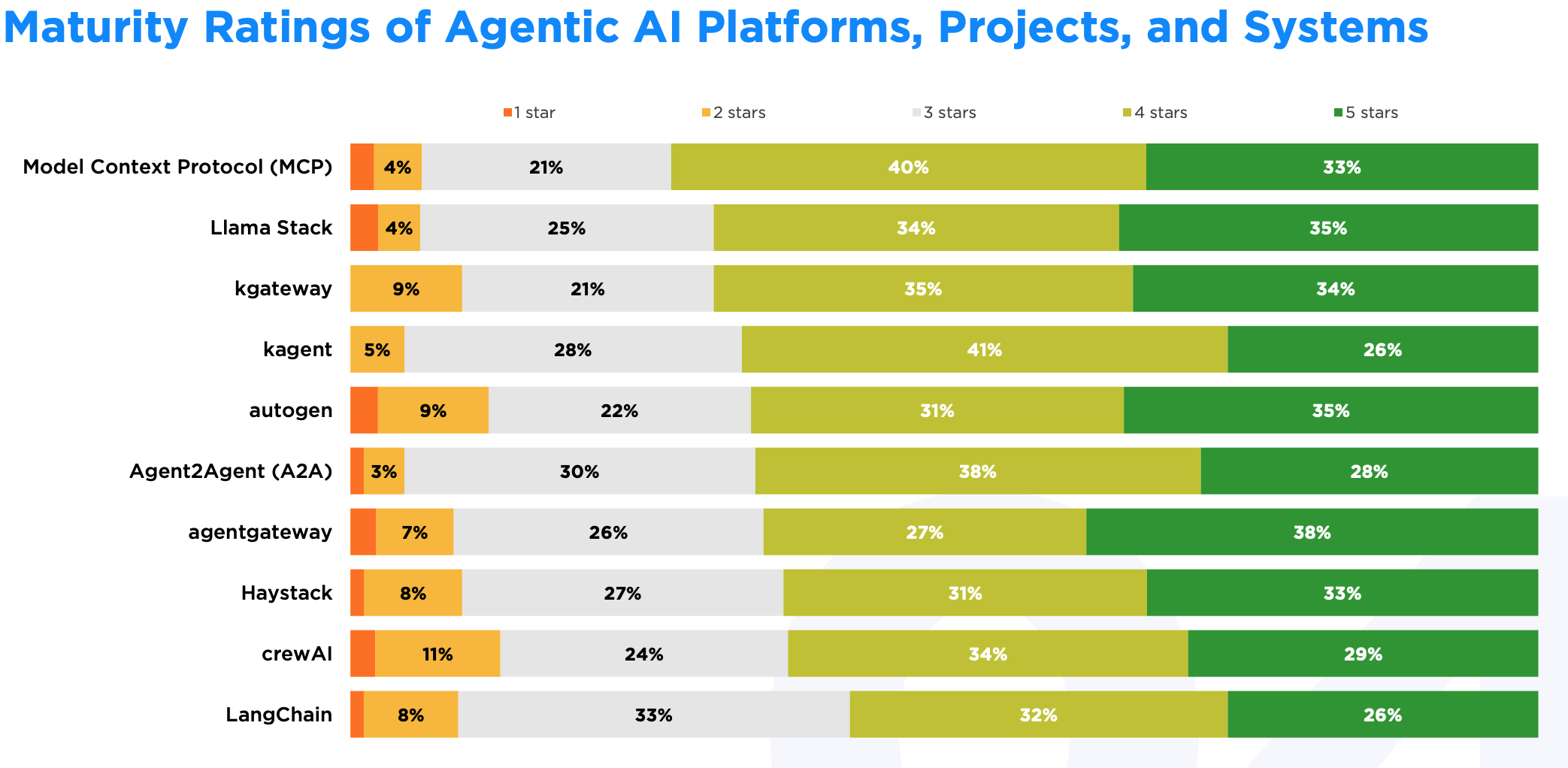
LangChain 在成熟度上表现不太好。开发者反映 LangChain 难以适配企业环境,扩展时会碰到各种可靠性和稳定性问题,而这些问题刚好是成熟度评估的核心。
实用性如何?
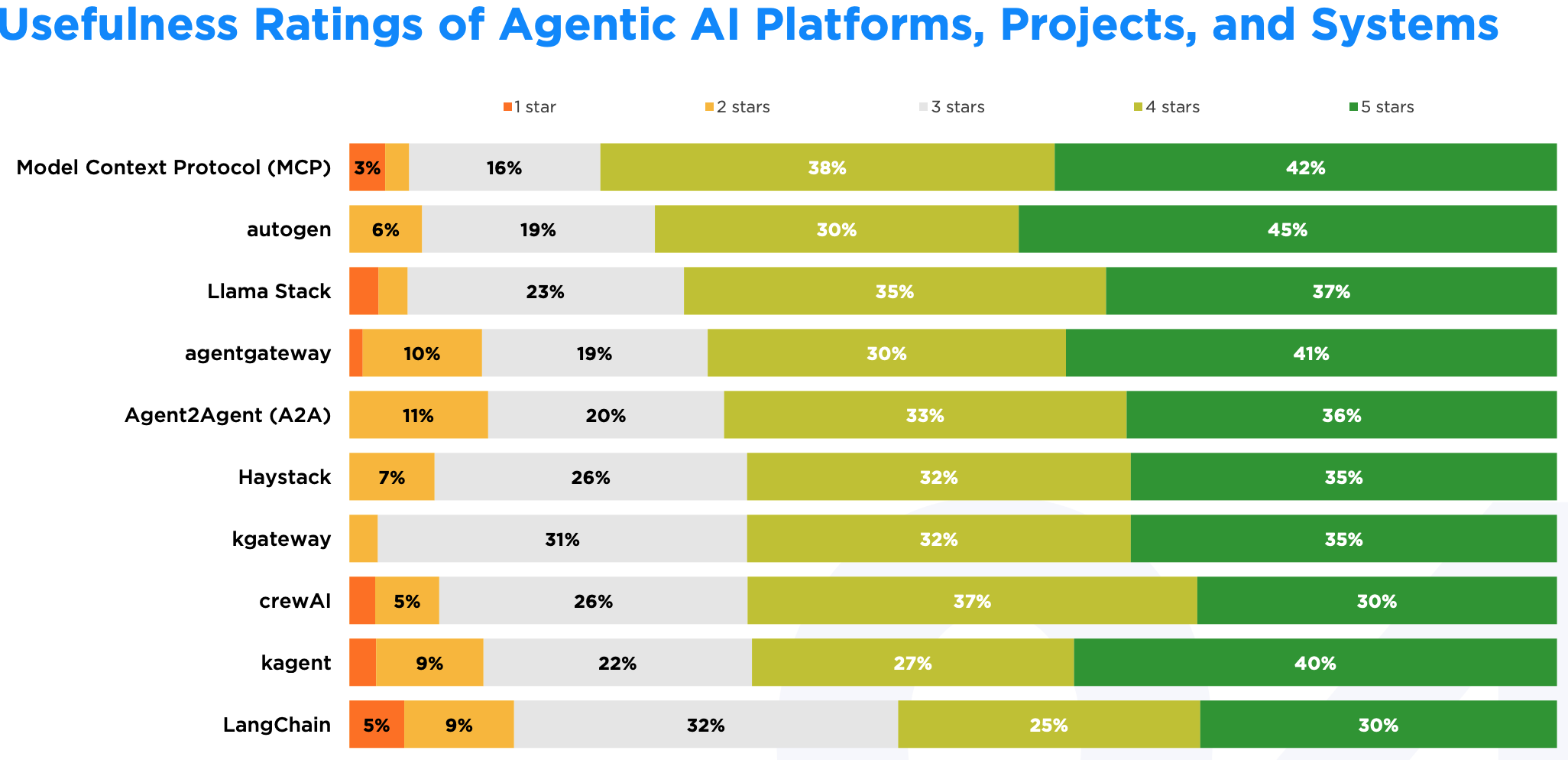
autogen 的 5 星评价比例最高(45%),但 MCP 的 4-5 星综合好评率排名第一。MCP 用户基数更大,具有更广泛的实用性;而 autogen 则在多代理编排这一专业社区中获得了高度认可。
MCP 的高分和庞大的用户基础表明,结构化、基于 Agent 的设计正在企业级场景中得到实际应用。
推荐意愿
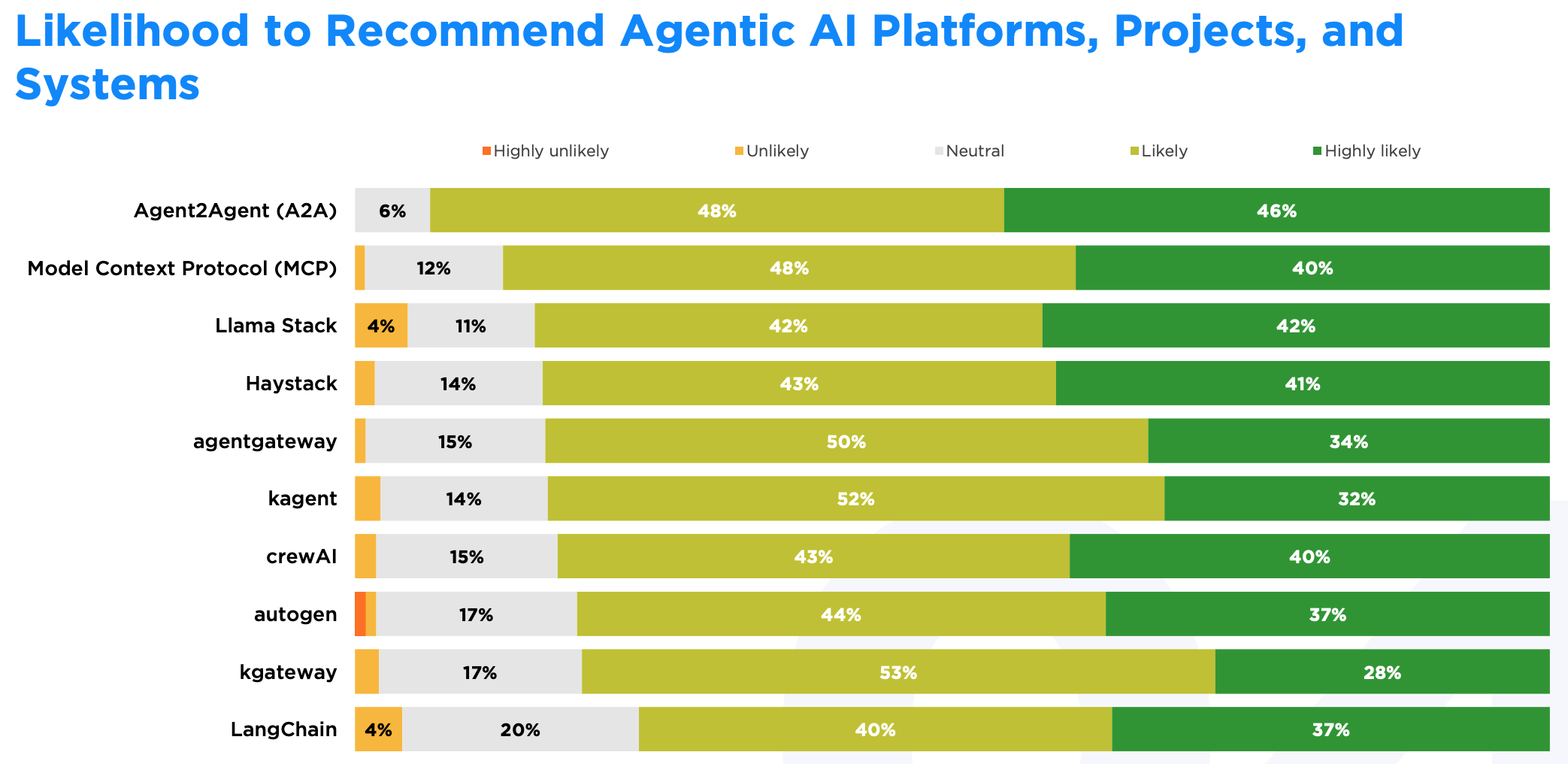
Agent2Agent(A2A,Linux Foundation 项目)在用户推荐意愿方面表现突出,94%的用户愿意推荐。作为一款全新的工具,A2A在功能和可靠性上可能还有提升空间,但开发者认为其发展路线清晰,并对其与现有项目的集成效果较为满意,因此愿意推荐给他人。
写在最后
看完这份报告,有几点感受想跟你分享。
首先,这次调研的项目其实不全是 Kubernetes 或者云原生项目,但它们基本都用上了容器化、编排这些云原生的架构模式。这说明一个趋势:对 AI/ML 工作负载来说,云原生已经不是可选项了,而是必需品。不管你用不用 K8s,这套思路已经成为支撑 AI 系统运行和扩展的基础。
从评级结果看,NVIDIA Triton、Airflow、MCP 这些处于采纳级别的技术,靠的就是经过大量实际使用验证的可靠性。同时,一些新兴工具在代理架构和标准化协议方面也在持续创新,虽然还在试验阶段,但发展势头不错。
具体到技术选型,我的建议是:核心基础设施还是用采纳级别的成熟技术比较稳妥,出问题的概率小,社区支持也好。至于那些处于试验状态的工具,如果正好符合你的特定需求,也可以试试,但要做好踩坑的准备。关键是要根据自己团队的能力、业务场景和发展阶段来权衡,别人说好的不一定适合你。
最后说一句,技术选型真不能只看热度。这份报告的价值就在于它反映的是真实用户的使用体验,能帮你快速判断哪些技术在开发者社区里站得住脚,哪些可能还存在不少问题。AI/ML 这个领域变化太快,保持对社区动态的关注很有必要。
参考资料:
- CNCF技术雷达完整报告:https://www.cncf.io/reports/cncf-technology-landscape-radar-report/
- CNCF官方新闻稿:https://www.cncf.io/announcements/2025/11/11/cncf-and-slashdata-report-finds-leading-ai-tools-gaining-adoption-in-cloud-native-ecosystems/
- CNCF项目列表:https://www.cncf.io/projects/
欢迎长按下面的二维码关注 Feisky 公众号,了解更多云原生和 AI 知识。
