前 OpenAI 联合创始人、特斯拉前 AI 总监 Andrej Karpathy 又放大招了。继 nanoGPT 之后,他刚开源了 nanochat 项目。这是一个完整的 ChatGPT 克隆流程,包含从分词器、预训练、微调再到推理和 WebUI 的全套流程,整个项目只有大概 8000 行代码,刚刚开源就已经获得 1 万多星了。

之前的 nanoGPT 项目只涵盖了预训练阶段,而 nanochat 提供了完整的全栈实现。你可以在云服务商租个带有 8 个 H100 的 GPU 节点,然后只需要训练 4 小时就能得到一个 ChatGPT 克隆,总成本只有 $100。
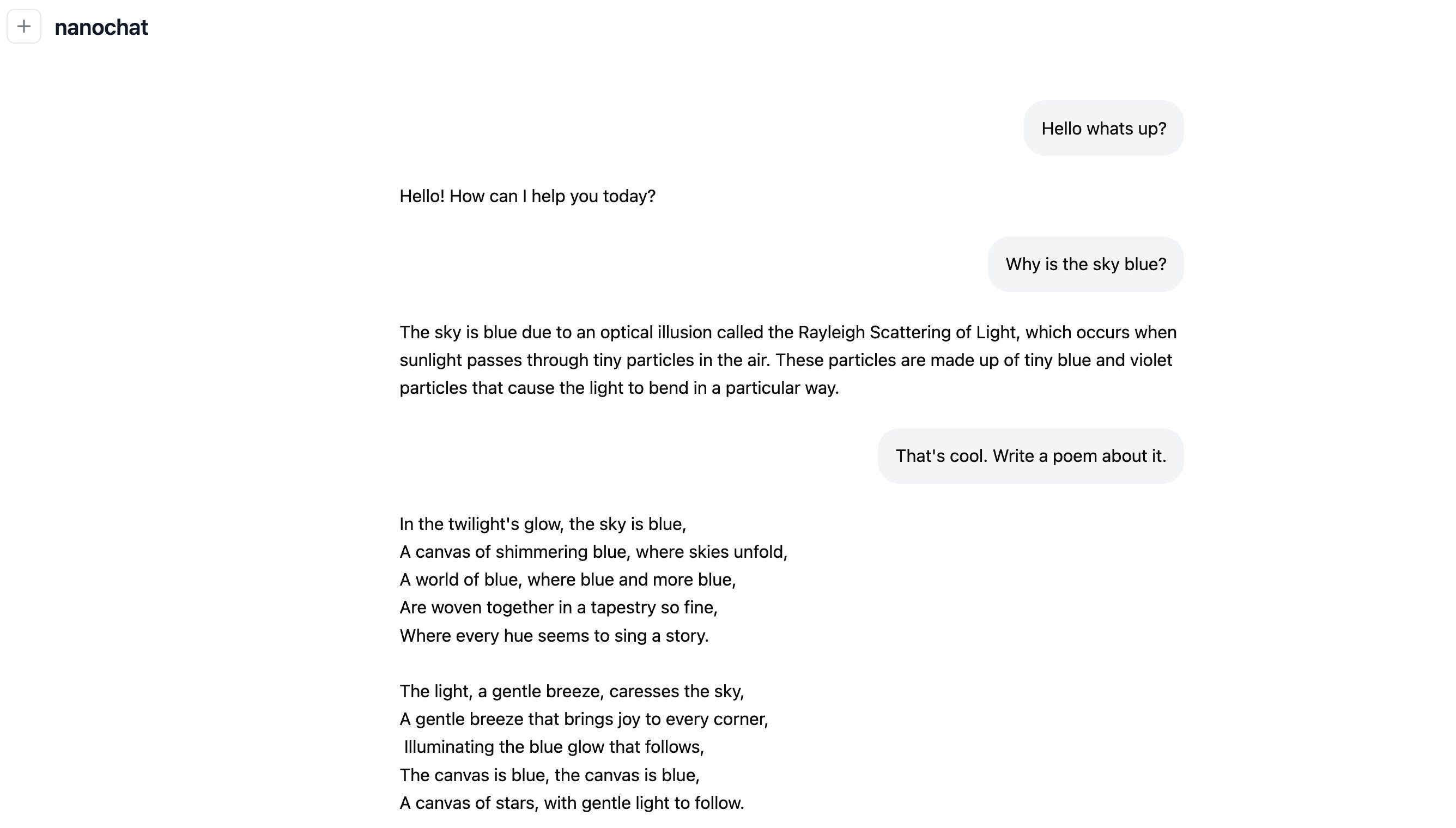
为什么需要 nanochat?
之前想要训练一个类似 ChatGPT 的模型,你需要东拼西凑各种工具和代码库:分词器、预训练、微调、推理等各个阶段都需要不同的工具。并且每个工具都有自己的依赖和配置方式,整合起来非常麻烦。
而 nanochat 把整个流程都塞进了一个干净的代码库,你不需要理解复杂的分布式训练框架,也不用搞清楚各种工具之间的接口。脚本拿来跑几个小时,所有步骤就自动完成了。
更重要的是,这个项目的目标是“可读、可 hack、可 fork”。代码写得很清晰,注释也详细,很适合用来学习 LLM 训练的完整流程。Karpathy 说这会成为 LLM101n 课程的压轴项目(课程仍在开发中)。
nanochat 包含什么?
整个 nanochat 代码库大约 8000 行代码,主要是 Python(基于 PyTorch),外加一点 Rust 用来训练分词器。代码写得挺干净,Karpathy 自己说这是他写过的“最疯狂的项目之一”。
1. 训练分词器
用 Rust 实现了一个新的分词器训练工具。分词器是 LLM 的第一步,把文本转换成 token 序列。
2. 预训练 Transformer
在 FineWeb 数据集上预训练 Transformer 模型。FineWeb 是一个高质量的网页文本数据集,nanochat 默认用了其中约 24GB 的数据(来自 karpathy/fineweb-edu-100b-shuffle)。训练完成后会在多个指标上评估 CORE score。
3. 中间训练和微调
预训练之后,模型会经过三个阶段:
中间训练(Midtrain):在 56.8 万个样本上训练,包括:
- SmolTalk 的 46 万条对话数据
- MMLU 的 10 万道辅助训练题
- GSM8K 的 8000 道数学题
监督微调(SFT):在 2.14 万个精选样本上微调,包括:
- ARC-Easy:2300 题(简单的常识推理)
- ARC-Challenge:1100 题(困难的常识推理)
- GSM8K:8000 道数学题
- SmolTalk:1 万条对话
微调完成后会在多个基准上评估,包括世界知识多选题(ARC-E/C、MMLU)、数学能力(GSM8K)、代码能力(HumanEval)。
4. 强化学习优化(可选)
可以选择用 GRPO 算法在 GSM8K 上做强化学习优化。GRPO 是一种简单的强化学习方法,能提升模型在数学问题上的表现。
5. 推理引擎和 WebUI
训练完成后,nanochat 提供了一个高效的推理引擎:
- KV cache:缓存注意力的键值对,加速推理生成;
- Prefill 和 Decode:分离预填充和解码;
- 工具调用:内置轻量级沙盒 Python 解释器;
- 多种界面:命令行(CLI)或同 ChatGPT 类似的 WebUI。
WebUI 的代码很简洁,服务端是个简单的 Python 服务器,前端是纯 JavaScript 写的,代码量不多。
6. 自动生成报告卡
整个流程跑完后,nanochat 会生成一个 Markdown 格式的报告卡,总结模型的各项指标,并以“游戏化”的方式呈现整个内容。
怎么用 nanochat?
nanochat Github Repo 已经封装好了所有流程,所以用起来还是比较简单的:
1. 租个云 GPU 节点
Karpathy 推荐用 8XH100 的节点,大概 $24/小时。当然你也可以用其他 GPU,只是训练时间可能会有所不同。
2. 克隆代码库
git clone https://github.com/karpathy/nanochat.git
cd nanochat
3. 运行训练脚本
安装 uv、Rust 等必需的开发依赖后执行下面的脚本开始训练:
bash speedrun.sh
因为脚本要跑 4 小时,Karpathy 推荐在 screen 会话里运行,方便后台执行:
screen -L -Logfile speedrun.log -S speedrun bash speedrun.sh
这样你可以用 Ctrl-a d 脱离会话,然后 tail speedrun.log 查看进度。脚本会自动完成所有步骤:下载数据、训练分词器、预训练、微调以及评估等。
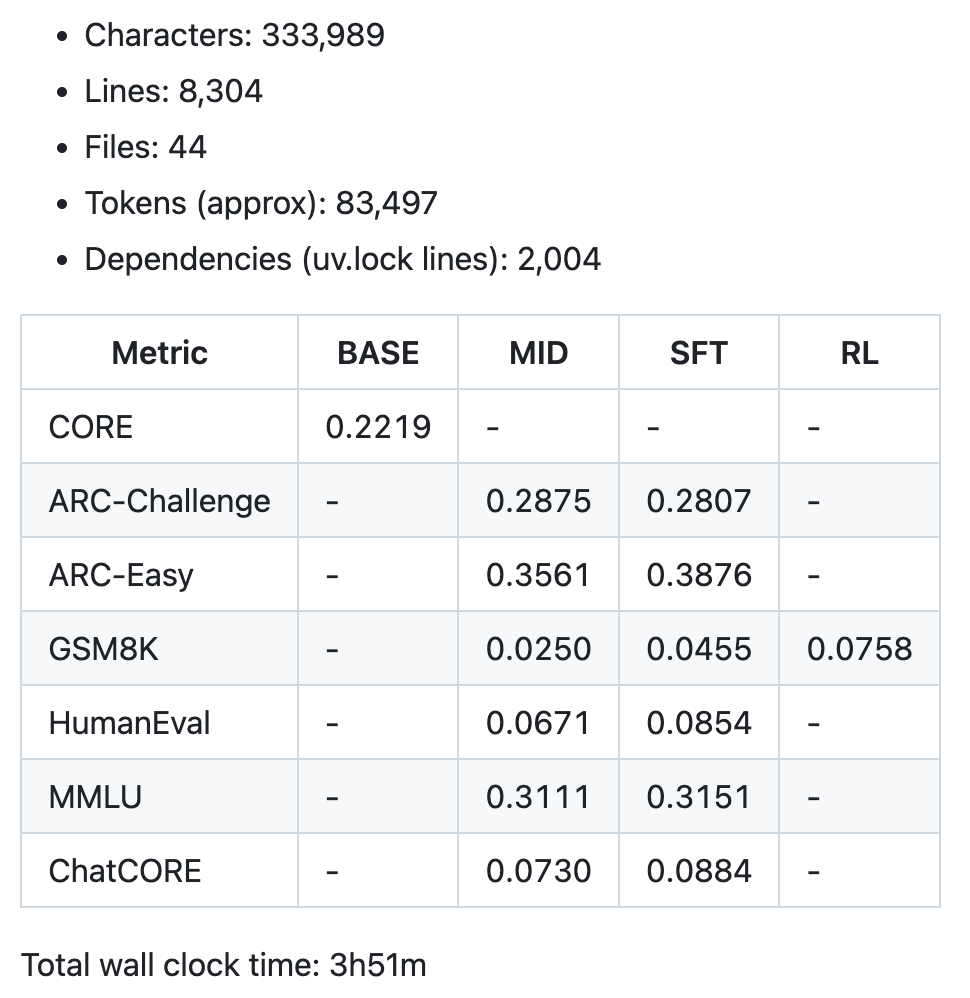
4. 查看训练报告
训练完成后,项目目录会生成 report.md 文件,包含完整的评估指标。文件末尾会有一个汇总表格,类似这样:
5. 启动推理服务
激活 Python 虚拟环境,启动 WebUI:
source .venv/bin/activate
python -m scripts.chat_web
然后在浏览器访问显示的 URL。如果在云服务器上,记得用公网 IP 加端口,比如 http://209.20.xxx.xxx:8000/。
性能和成本
根据 Karpathy 的测试,不同训练时长能得到不同水平的模型。
4 小时(depth=20,约 $100):能进行基本对话,写简单的故事或诗歌,你可以感觉在跟幼儿园小朋友聊天。
12 小时(depth=26,约 $300):在 CORE 指标上超过 GPT-2,对话更连贯,并能处理更复杂的问题;
24 小时(depth=30,约 $1000):FLOPs 相当于 GPT-3 Small(125M 参数),是 GPT-3 的 1/1000,MMLU 40+ 分,ARC-Easy 70+ 分,GSM8K 20+ 分,可以解决简单的数学和代码问题。
从这个梯度来看,随着训练时间增加,模型能力提升很快。不过这些微模型和真正的 GPT-3/4 还是没法比,毕竟规模差了好几个数量级。
模型架构
nanochat 的模型架构类似 Llama,但做了一些简化和调整。Karpathy 说他尝试为这个规模找到一个可靠的基准配置(solid baseline)。
Speedrun 模型参数(深度 20):
- 20 层 Transformer
- 1280 维度
- 10 个注意力头
- 约 5.6 亿参数(560,988,160)
- 分词器词汇表:65,536 tokens
- 压缩比:4.8 字符/token
架构特点:
- Dense Transformer
- 旋转位置编码(RoPE),不用传统的位置嵌入
- QK 归一化
- 嵌入和去嵌入层不共享权重
- Token 嵌入后做归一化
- MLP 用 ReLU² 激活函数
- RMSNorm 没有可学习参数
- 线性层没有偏置项
- 多查询注意力(MQA)
- Logit softcap
优化器:Muon + AdamW,受 modded-nanoGPT 影响。Karpathy 说他的 TODO 列表里还有“调优 Adam 的学习率,尝试移除 Muon”。
结语
虽然 nanochat 还在开发中,还有很多问题等待优化,但它是第一个提供端到端完整 ChatGPT 克隆的开源项目,非常适合用来学习 LLM 训练的完整流程。
当然,你也别指望单纯拿 nanochat 在自己的数据上训练就可以得到一个自己风格的模型。因为本质上 nanochat 还只是一个小模型(或者叫微模型更确切),只能达到幼儿园水平,离成年人智力还差得远。所以,像这种需求还是用顶级大模型做微调或者使用 NotebookLM/RAG 之类的技术更容易实现。
相关资源:
- GitHub 仓库:https://github.com/karpathy/nanochat
- 详细技术介绍:https://github.com/karpathy/nanochat/discussions/1
- Karpathy 的 Twitter:@karpathy
- LLM101n 课程:https://github.com/karpathy/LLM101n
欢迎长按下面的二维码关注 Feisky 公众号,了解更多云原生和 AI 知识。
