最近在使用 Gemini CLI 时,相信不少开发者都遇到过这样的困扰:明明设置了 Gemini 2.5 Pro 模型,却发现在使用过程中很快就降级到了 Gemini 2.5 Flash,导致生成质量明显下降。这种 “智能降级” 机制背后的原理是什么?我们又该如何应对?
本文将深入分析 Gemini CLI 模型降智的触发机制,并提供经过验证的解决方案。
降智机制的技术原理
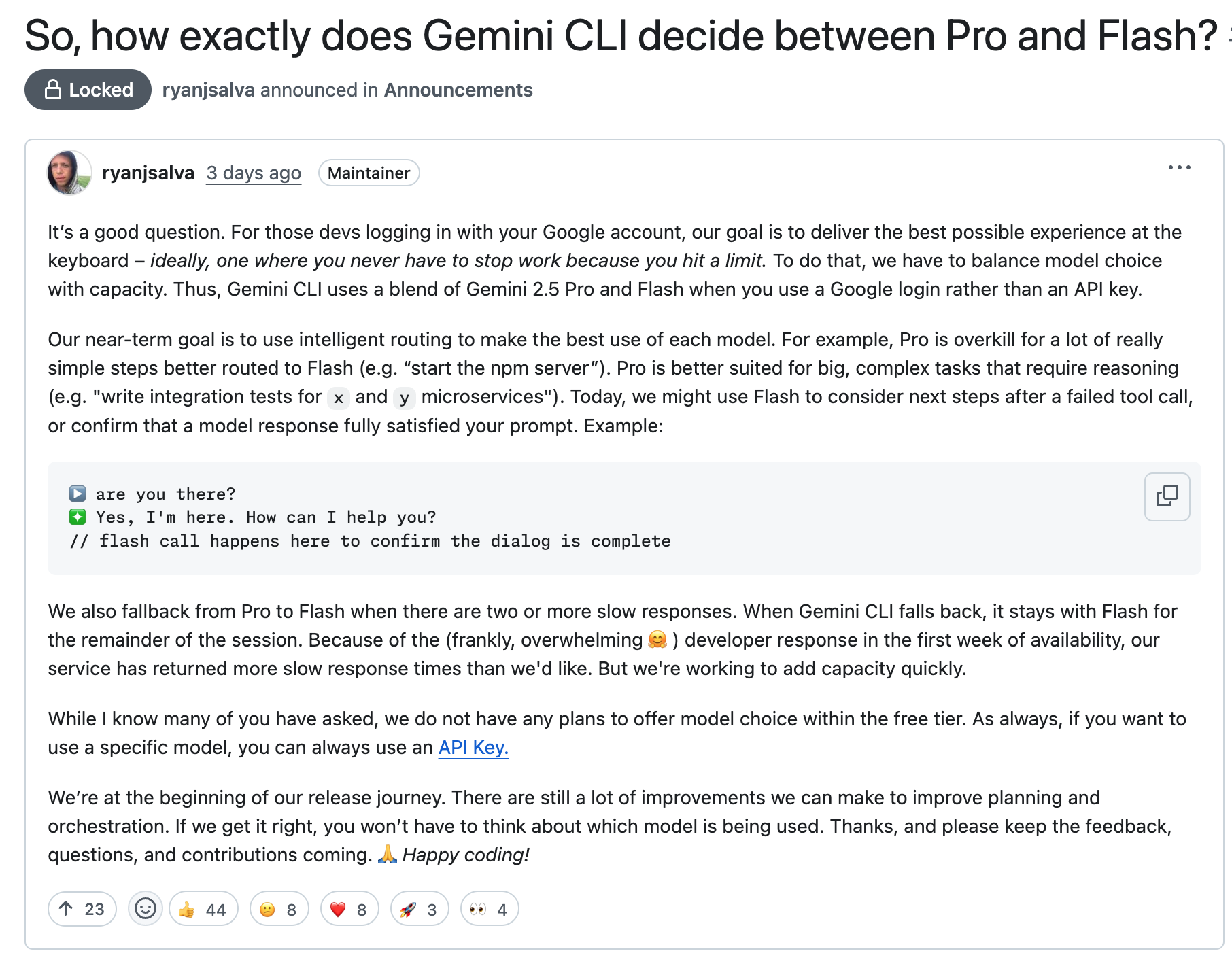
Google 在 Gemini CLI 中实现了一套智能模型路由系统,其核心目标是 平衡用户体验与系统容量。官方的设计哲学是:让开发者 “永远不会因为触及限制而被迫停止工作”。
具体触发条件
根据官方技术说明,模型降级主要由以下机制触发:
- 任务复杂度评估
- 简单任务:如
npm start、ls -la等基础操作,系统会自动选择 Flash 模型 - 复杂任务:如代码架构设计、多模块集成测试等,才会调用 Pro 模型
- 工具调用失败:当命令执行失败时,后续的错误分析步骤会使用 Flash 模型
- 性能监控机制
- 响应时间阈值:当检测到 连续两次或更多慢响应 时,系统自动从 Pro 切换到 Flash
- 会话级别锁定 :一旦在某个会话中触发降级, 整个会话期间都将保持使用 Flash 模型
- 系统容量压力
由于 Gemini CLI 发布初期用户激增,服务端容量压力导致响应时间超出预期阈值,进而触发大规模降级。
这种设计实际上是一个典型的 服务降级策略:通过智能降级来维护整体系统稳定性,避免在高负载时完全崩溃。从产品角度看,这是一种合理的工程权衡。
如何解决降智问题?
临时缓解技巧
对于免费用户来说,可以采用以下临时措施来缓解降智问题:
| 场景 | 解决方案 |
|---|---|
| 响应时间接近阈值 | 减少单次会话的上下文量,使用 /stats 监控 token 使用情况 |
| 遇到 429 限流 | 让 CLI 空闲 10-15 秒后再发送指令,或降低并发请求频率 |
| 偶发降级恢复 | 退出 Gemini CLI 再重新打开 |
除了这些方法之外,还有一些更稳定的方案。
方案一:切换到 API 密钥认证(推荐)
官方明确区分了 OAuth 登录和 API 密钥两种认证方式的行为差异。使用 API 密钥时,模型选择权限更加明确。
详细配置步骤:
1. 获取 API 密钥
访问 Google AI Studio 创建 API 密钥:
- 登录 Google AI Studio
- 点击 “Create API key” 按钮
- 选择现有项目或创建新项目
- 复制生成的 API 密钥
2. 配置环境变量
临时配置(当前会话有效):
export GEMINI_API_KEY="your_api_key_here"
永久配置(推荐):
选择以下方式之一:
方式一:添加到 shell 配置文件
# 对于 bash 用户
echo 'export GEMINI_API_KEY="your_api_key_here"' >> ~/.bashrc
# 对于 zsh 用户
echo 'export GEMINI_API_KEY="your_api_key_here"' >> ~/.zshrc
# 重新加载配置
source ~/.bashrc # 或 source ~/.zshrc
方式二:使用 .env 文件
在项目目录或家目录创建 .env 文件:
# 项目级别配置
mkdir -p .gemini && echo "GEMINI_API_KEY=your_api_key_here" > .gemini/.env
# 或全局配置
mkdir -p ~/.gemini && echo "GEMINI_API_KEY=your_api_key_here" > ~/.gemini/.env
3. 切换认证方式
如果之前使用 Google 账户登录,需要重新配置使用 API Key
/auth
# 选择 Gemini API Key (AI Studio)
方案二:编译 –force-model 开关(进阶)
社区贡献的 PR #2278 为 CLI 增加了强制模型锁定功能。
编译步骤:
git clone https://github.com/google-gemini/gemini-cli
cd gemini-cli && git checkout refs/pull/2278/head
npm install && npm run build && npm link
使用方式:
gemini --force-model
限制:
- 目前仅支持 API Key 认证方式;
- PR 尚未正式合并,存在版本兼容风险;
- 需要自行维护编译版本。
方案三:直接修改源代码(高阶)
Gemini CLI 源代码中定义了 DEFAULT_GEMINI_FLASH_MODEL = 'gemini-2.5-flash' 作为降级的模型,把这个模型替换为 gemini-2.5-pro 也可以避免降级问题:
cd $(npm root -g)/@google/gemini-cli
grep -rl --exclude-dir=test "DEFAULT_GEMINI_FLASH_MODEL = 'gemini-2.5-flash'" \
| xargs sed -i.bak "s|DEFAULT_GEMINI_FLASH_MODEL = 'gemini-2.5-flash'|DEFAULT_GEMINI_FLASH_MODEL = 'gemini-2.5-pro'|g"
grep -rl --exclude-dir=test 'DEFAULT_GEMINI_FLASH_MODEL = "gemini-2.5-flash"' \
| xargs sed -i.bak 's|DEFAULT_GEMINI_FLASH_MODEL = "gemini-2.5-flash"|DEFAULT_GEMINI_FLASH_MODEL = "gemini-2.5-pro"|g'
限制:
- 需要对 Gemini CLI 源代码比较熟悉(可以借助 Gemini CLI 来读代码);
- 源码可能随时修改,这个方法不确保一直有效,并且每次 Gemini CLI 升级之后需要再次修改。
最佳实践建议
- 优先使用 API 密钥认证,避免 OAuth 降级机制
- 控制单次会话的上下文长度,及时使用
/clear清理历史 - 遇到降级时立即重启会话,而不是继续使用 Flash 模型
- 大规模使用的话,建议开启计费账户确保服务稳定性和更高的配额限制
日常使用技巧
- 监控模型状态:定期使用
/stats查看当前使用的模型和 token 消耗 - 合理拆分任务:将复杂任务分解为多个小任务,避免单次请求过大
- 及时清理会话:发现性能下降时使用
/clear或重启 CLI
通过这些实践,可以最大化 Gemini CLI 的使用效果,避免因模型降级影响开发效率。
欢迎长按下面的二维码关注 Feisky 公众号,了解更多云原生和 AI 知识。
