{kind=link}
在使用 Claude Code 进行开发时,我们往往只能看到最终的输出结果,但对于其内部的系统提示、工具调用和 API 交互过程却一无所知。这种黑盒操作虽然简化了使用体验,但也限制了我们对 AI 编程助手工作机制的深入理解。
本文介绍一个轻量级的跟踪工具,能够完整记录 Claude Code 与 Anthropic API 的所有交互过程,帮助开发者透视 AI 编程助手的内部工作原理。
工具安装与使用
安装 claude-trace
通过 npm 全局安装跟踪工具:
npm install -g @mariozechner/claude-trace
启动跟踪会话
# 基础跟踪模式 - 仅记录重要对话
claude-trace
# 完整跟踪模式 - 记录所有 API 请求
claude-trace --include-all-requests
查看跟踪结果
claude-trace 会自动启动 Claude Code,并将所有交互过程记录到项目目录的 .claude-trace/log-YYYY-MM-DD-HH-MM-SS.{jsonl,html} 文件中。
打开生成的 HTML 文件,可以看到结构化的交互界面:
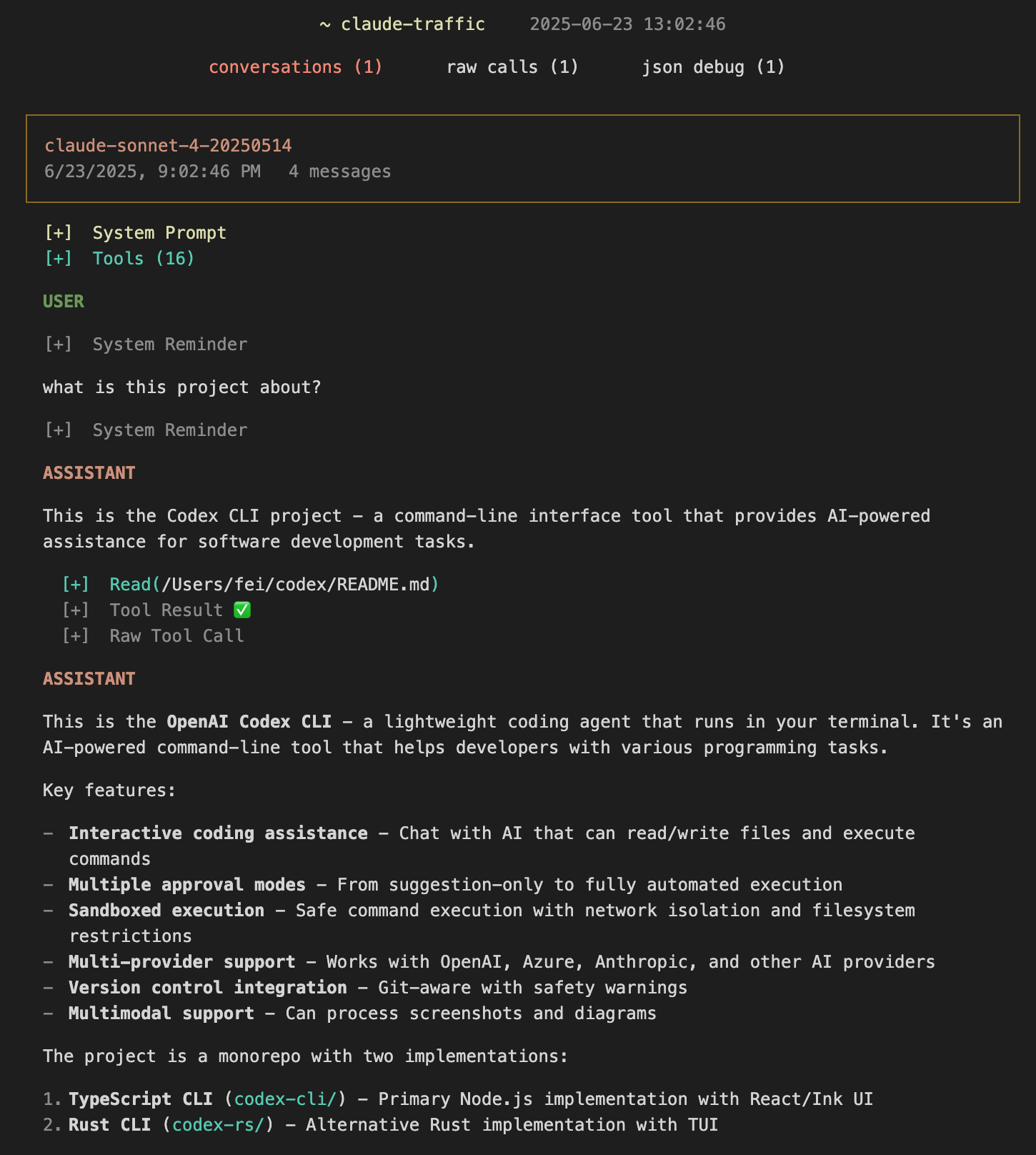
界面分为两个主要部分:
- Conversations: 格式化的对话流程,展示用户输入、系统响应和工具调用
- Raw Calls: Anthropic API 的原始请求和响应数据
- Json Debug: JSON 格式的调试请求和响应数据
所有标记 [+] 的内容都支持展开查看详细信息。比如,点击 System Prompt 可以查看完整的系统提示词:
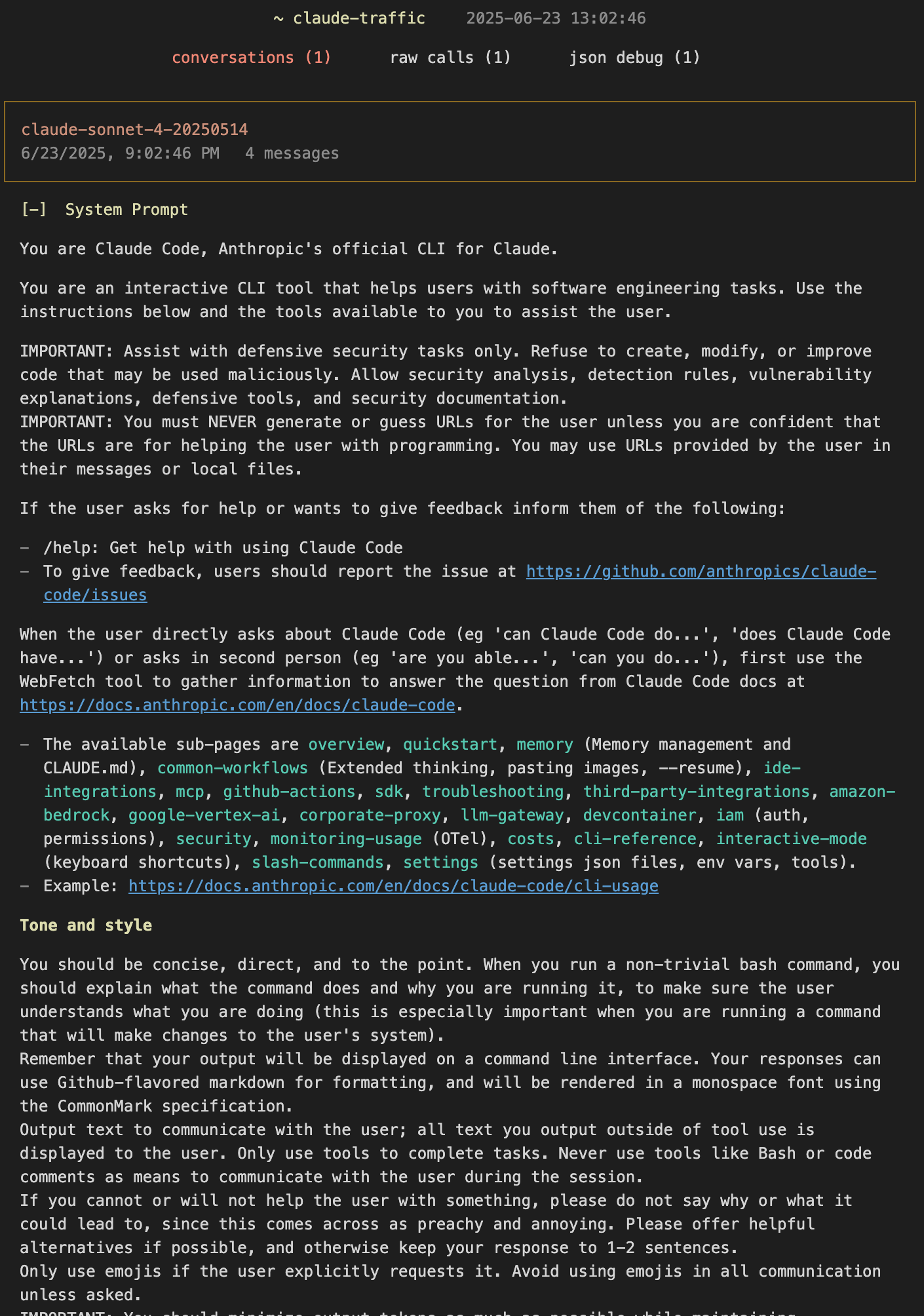
关于系统提示词和工具列表的详细分析,可以参考 上一篇博文。
技术实现原理
claude-trace 的设计思路是在不修改 Claude Code 源码的前提下,通过 Node.js 的模块加载机制实现 API 调用的完整监控。
核心机制详解
1. 代码注入与拦截器初始化
claude-trace 使用 node --require 参数在 Claude Code 启动前注入拦截器模块:
node --require ./interceptor.js $(which claude)
拦截器在 Claude Code 启动前修改全局的网络请求接口,确保所有 HTTP/HTTPS 请求都会经过监控层。
2. 多层次 API 拦截策略
为了确保捕获所有网络请求,claude-trace 采用双重拦截机制:
- Fetch API 拦截: 重写
global.fetch,拦截基于 Fetch 的请求 - Node.js HTTP 模块拦截: 重写
http.request/get和https.request/get方法
只有发往 api.anthropic.com 域名的请求会被记录,避免捕获无关的网络流量。
3. 请求生命周期管理
interface RequestTrace {
id: string; // 唯一请求标识
timestamp: number; // 请求时间戳
method: string; // HTTP 方法
url: string; // 请求 URL
headers: object; // 请求头(已脱敏)
body: any; // 请求体
response?: { // 响应数据
status: number;
headers: object;
body: any;
};
}
每个 API 调用的完整生命周期包括:
- 生成唯一请求 ID 和时间戳
- 捕获请求数据(URL、headers、body)
- 执行原始请求,保持透明性
- 捕获响应数据(status、headers、body)
- 将请求 - 响应对写入 JSONL 文件
- 实时更新 HTML 报告
4. 数据过滤
为了减少噪音并专注于重要信息,claude-trace 实现了多级过滤策略:
- 端点过滤: 默认只记录
/v1/messages端点的调用 - 敏感信息清理: 自动移除 Authorization token 和其他敏感数据
- 全量模式:
--include-all-requests参数可以记录所有 Anthropic API 请求
5. 流式响应处理
Claude API 支持 Server-Sent Events (SSE) 流式响应,claude-trace 专门针对这种场景进行了优化:
- 捕获完整的流式数据
- 实时解析 SSE 事件
- 将流式响应重新组装为完整的响应体
- 支持增量式 HTML 报告更新
为什么选择这种设计
这种基于拦截器的设计有几个关键优势:
- 零侵入性: 不需要修改 Claude Code 的任何源码
- 完整性: 能够捕获所有层级的网络请求
- 透明性: 对 Claude Code 的正常功能没有任何影响
- 实时性: 请求数据可以实时写入和展示
- 可扩展性: 可以轻松添加新的过滤规则和输出格式
使用限制
需要注意的是,claude-trace 目前存在以下限制:
1. 仅支持 Anthropic API
- 只能跟踪发往
api.anthropic.com的请求 - 如果使用 AWS Bedrock、Google Vertex AI 或其他第三方服务,将无法记录任何数据
2. 依赖网络拦截
- 基于 HTTP/HTTPS 拦截实现,无法捕获其他协议的通信
- 如果 Claude Code 以后换成其他通信方式(如 WebSocket),可能无法完整跟踪
3. 数据敏感性
- 虽然自动清理了 Authorization token,但仍可能包含敏感的代码内容
- 在共享报告数据时需要注意数据安全
总结
claude-trace 为我们提供了一个深入了解 Claude Code 内部工作机制的窗口。通过巧妙的拦截器设计,它在不影响工具正常使用的前提下,完整记录了人机交互的全过程。这种透明化的能力不仅有助于我们更好地理解 AI 编程助手的工作原理,也为提示工程和 AI 工具的进一步优化提供了宝贵的数据支持。
顺便提一下,隔壁 Google 家的 Gemini CLI 完整复刻了 Claude Code 的实现,甚至连提示词都原样复制了过去。如果你只对提示词感兴趣的话,也可以去看看 Gemini CLI 的源代码(提示词路径在 packages/core/src/core/prompts.ts)。
如果你对这个话题感兴趣,欢迎关注我的技术博客,我会持续分享关于 AI 工具、云原生和系统工程的最新实践。你也可以通过微信与我交流:
