
{kind=link}
当所有人都在讨论 AI 会不会取代程序员时,Andrej Karpathy 扔出了一个更炸裂的观点:程序员这个职业正在消失,但不是你想的那样——因为每个会说话的人都正在变成程序员。
“The hottest new programming language is English”,这条推文至今还钉在 Karpathy 的 Twitter 置顶。这位特斯拉前 AI 总监、OpenAI 联合创始人,在旧金山 AI Startup School 的主题演讲中,用一句话概括了正在发生的软件革命:我们不再需要学 Python 或 JavaScript,只要会说话,就能编程,软件开发已经进入 3.0 时代。

本文根据 Andrej Karpathy 演讲的内容进行编译和整理。如果有兴趣的话,建议去看视频版全文 https://www.youtube.com/watch?v=LCEmiRjPEtQ。
软件演化三部曲
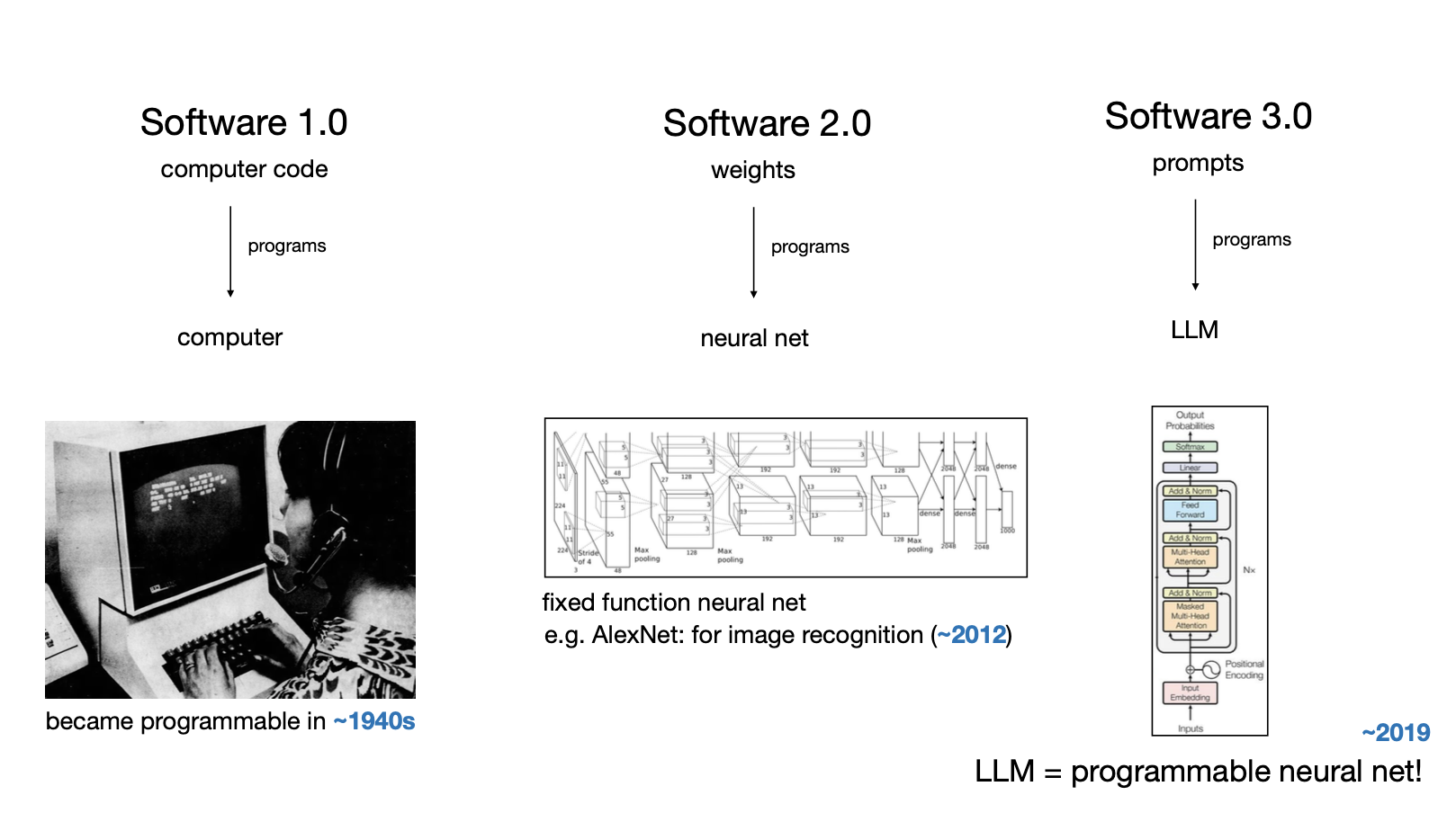
1. Software 1.0:手工编织的数字世界
这是我们最熟悉的传统软件时代。工程师们像工匠一样,用 C++、Python 等语言精心编写每一行代码,为计算机提供明确而详细的指令。如果你使用过“Map of GitHub”这样的可视化工具,就能直观地感受到人类为数字世界编写的海量代码——它们构成了我们数字生活的基石。
2. Software 2.0:让机器学会学习
过去几年,我们迈入了软件 2.0 时代。这个时代的核心不再是人类编写的代码,而是神经网络的权重参数。工程师的角色发生了微妙的转变:从“编程者”变成了“训练师”。我们不再直接告诉计算机该怎么做,而是精心准备数据集,让神经网络自己学会完成任务。
Karpathy 分享了他在特斯拉开发自动驾驶系统时的亲身经历:随着神经网络能力的提升,大量传统的 C++ 代码被逐步移除,其功能被迁移到神经网络中。用他的话说,神经网络正在“吃掉”传统的代码栈。
3. Software 3.0:当编程变成对话
最具革命性的变化随着大型语言模型(LLM)的出现而到来。Karpathy 将此定义为软件 3.0 时代——一个用自然语言编程的时代。
想象一下:你不需要学习复杂的编程语言,只需用日常语言描述你想要的功能,LLM 就能理解并执行。这不是科幻,而是正在发生的现实。Karpathy 分享了一个生动的例子:他将 Manim 动画库的整个文档复制给 LLM,然后仅通过自然语言描述他想要的动画效果,LLM 就直接生成了完整的动画代码——他甚至不需要阅读那些繁琐的技术文档。
这意味着什么?任何会说话的人都可能成为“程序员”。编程的门槛被前所未有地降低了。
理解 LLM:不只是工具,更是新的计算平台
为了帮助我们理解 LLM 的本质,Karpathy 提供了几个富有洞察力的类比:
1. LLM 是新时代的“公用事业”
借用吴恩达“AI 是新电力”的说法,Karpathy 认为 LLM 正在成为像电力一样的基础设施。大型科技公司投入巨额资本训练模型(如同建设电网),然后通过 API 按使用量收费(如同电费)。我们对 LLM 的期待——低延迟、高可用性、稳定质量——也与对电力等公用事业的要求如出一辙。
但与传统公用事业不同的是,LLM 是纯软件,不受物理空间限制。这意味着我们可以同时使用多个 LLM 服务,在它们之间自由切换,避免被单一供应商锁定。
2. LLM 是新的“操作系统”
这是 Karpathy 认为最准确的类比。LLM 不再是简单的工具,而是日益复杂的软件生态系统:
- 系统架构:LLM 相当于 CPU,上下文窗口相当于内存,协调计算和存储来解决问题。
- 生态格局:商业方案(OpenAI 的 ChatGPT、Google 的 Gemini)与开源方案(Meta 的 Llama)并存,如同 Windows/Mac 与 Linux 的关系。
- 应用兼容性:就像你可以在不同操作系统上运行同一个应用,LLM 应用(如 Cursor)也可以通过下拉菜单在不同的 LLM 上运行。
我们正处于 LLM 的“1960 年代”:计算资源昂贵且集中化,所有人都通过网络与云端的 LLM 交互,就像早期的分时系统。个人计算革命尚未到来,但 Mac mini 等设备已经显示出个人 LLM 计算的早期迹象。
3. LLM 的“认知心理学”

Karpathy 幽默地将 LLM 描述为“人类精神的随机模拟器”。它们展现出一种独特的“涌现心理学”:
超能力:
- 百科全书般的知识储备
- 惊人的记忆力,如同电影《雨人》中的天才
- 瞬间处理和生成文本的能力
认知缺陷:
- 幻觉:会编造看似合理但实际错误的信息
- 锯齿状智能:在某些领域表现卓越,在其他方面却会犯低级错误(比如坚持 9.11 大于 9.9)
- 顺行性遗忘症:无法通过经验积累形成长期记忆,每次对话都是全新开始,就像电影《记忆碎片》的主角
- 安全漏洞:容易被精心设计的提示词欺骗或操纵
理解这些特性对于有效使用 LLM 至关重要。我们需要学会利用它们的超能力,同时规避其认知缺陷。
机遇:构建人机协作的未来
面对这场变革,最大的机遇在哪里?Karpathy 给出了明确的答案:部分自治应用(Partial Autonomy Apps)。
什么是部分自治?
理想的 AI 应用不是完全自主的机器人,而是像“钢铁侠战衣”——既能增强人类能力(Tony Stark 驾驶它),也能在需要时自主行动(战衣自动飞来找 Tony)。这种设计理念体现在几个关键特性上:
- 智能的上下文管理:应用自动处理大量信息和上下文,避免用户手动管理。
- 协调多重 LLM 调用:如 Cursor 后台协调嵌入模型、聊天模型、代码 diff 模型等。
- 优化的用户界面:GUI 至关重要,利用人类视觉处理能力快速验证 AI 输出。看代码 diff 的红绿标记比阅读文本描述更高效,按 Command+Y 接受或 Command+N 拒绝比打字更快。
- 可调节的自主性:提供“自主性滑块”——从 Tab 补全(用户主导)到 Command+K(修改代码块)到 Command+L(修改整个文件)再到 Command+I(全仓库级别修改)。
成功案例:
- Cursor:提供不同层级的编程辅助,从简单补全到全项目修改。
- Perplexity:提供快速搜索、研究模式、深度研究等不同自主性级别。
为什么是“部分”而非“完全”自治?
Karpathy 以他在特斯拉开发自动驾驶的多年经验为例,指出完全自主系统的实现极其困难。他分享了一个有趣的故事:2013 年,他在朋友的 Waymo 自动驾驶车中体验了 30 分钟的完美驾驶,零干预。当时他认为自动驾驶即将到来,但 12 年后的今天,我们仍在努力解决这个问题。
那些预言“2025 年是 AI 代理年”的说法过于乐观——这更可能是“AI 代理的十年”。
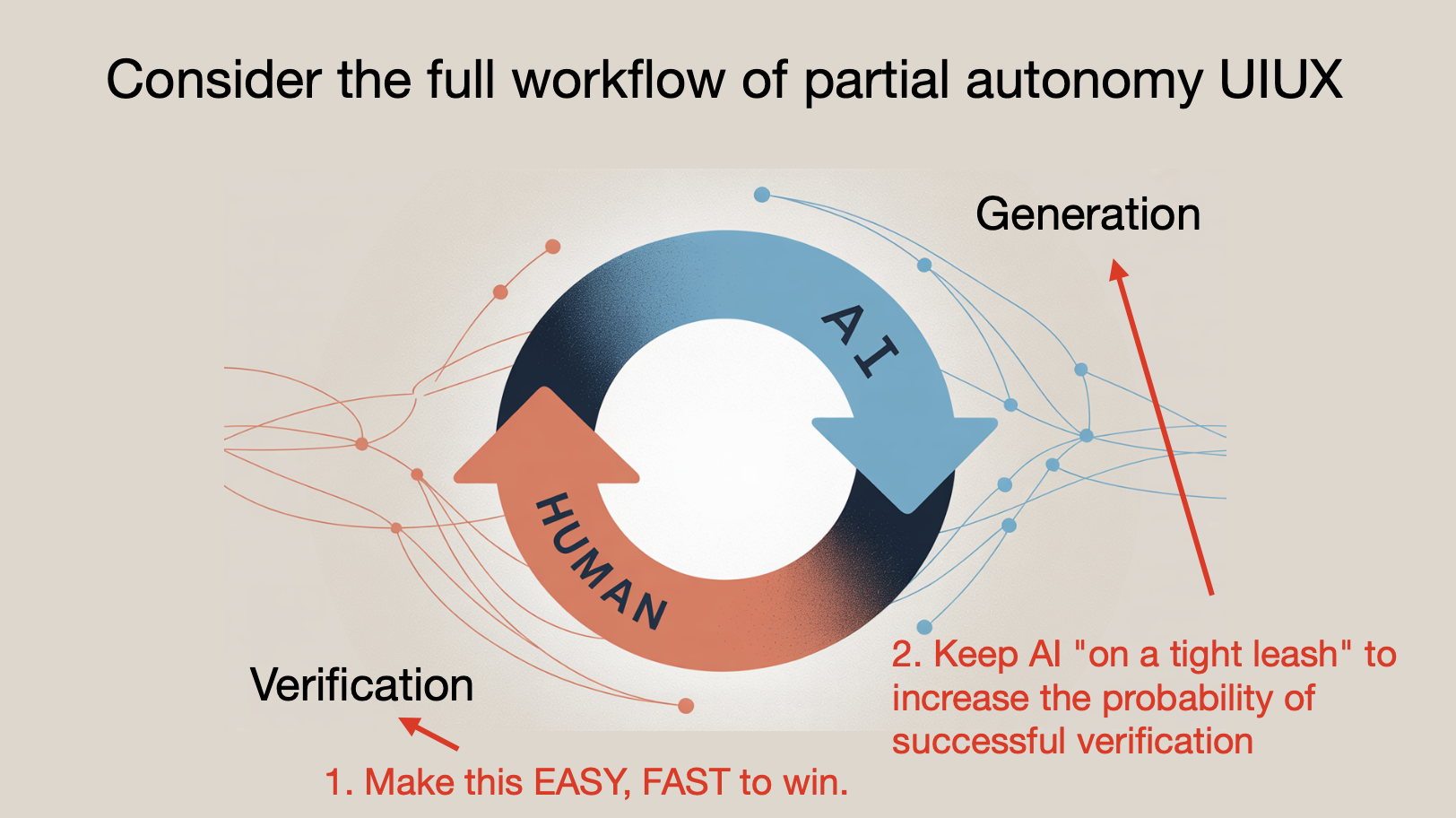
核心原则:加速“生成 - 验证”循环
在人机协作中,AI 负责生成,人类负责验证。成功的关键是:
- 加快循环速度:利用 GUI 和视觉表示让人类能快速验证 AI 输出。
- 牵住 AI 的缰绳:避免 AI 生成过大的输出(如 1 万行代码 diff),保持人类可控性。
- 小步迭代:采用小块、具体的任务,确保每步都能验证。
Vibe Coding:人人都是程序员的时代
当编程语言变成英语,一个前所未有的现象出现了——任何会说话的人都可以成为程序员。这种完全凭直觉和想象力进行编程的方式,Karpathy 给它起了一个极其生动的名字:Vibe Coding。
什么是 Vibe Coding?
Vibe Coding 的概念源自一条看似随意的推文,但却意外地成为了一个主流网络迷因,甚至有了自己的维基百科页面。这个词汇完美地概括了一种全新的编程方式:不需要深厚的技术背景,仅仅凭借直觉和想法就能创造软件。
Karpathy 分享了一个令人感动的视频:孩子们在进行 Vibe Coding。他们不懂复杂的编程语法,但却能用自然语言描述自己的想法,然后看着这些想法变成真正的代码。“看到这个视频,你怎么能对未来感到悲观呢?”Karpathy 感慨道。
Vibe Coding 的魅力与挑战
创造的门槛被彻底打破
Karpathy 本人也是 Vibe Coding 的热衷实践者。他分享了自己的两个项目:
1. iOS 应用开发 虽然不会 Swift 编程,但 Karpathy 在一天内就构建出了一个可以在手机上运行的 iOS 应用。“我不需要花五天时间学习 Swift 才能开始”,他说。
2. Menu Generator 应用 这是一个更有趣的例子。Karpathy 遇到了一个实际问题:在餐厅看菜单时,不知道菜品长什么样。于是他用 Vibe Coding 开发了 Menu Generator——一个能够根据菜单照片生成菜品图片的应用。
从 Demo 到产品依然存在巨大鸿沟
但 Vibe Coding 也暴露了一个严重问题:代码本身很容易,但让应用真正可用却极其困难。
Karpathy 分享了一个让人哭笑不得的经历:Menu Generator 的核心功能几小时就完成了,但为了让它真正上线——添加用户认证、支付系统、域名配置、部署到云端——却花费了整整一周时间。
更令人沮丧的是,这些工作大部分都不是编程,而是在浏览器里点击各种按钮,跟随无数的配置指南。比如集成 Google 登录功能需要很多手动步骤:
- 进入 Google Cloud Console
- 点击这个下拉菜单
- 选择那个选项
- 转到另一个页面
- 点击另一个按钮…
“这太疯狂了!”Karpathy 抱怨道,“计算机在告诉我应该做什么操作,为什么不能让计算机自己去做呢?”
Vibe Coding 的未来意义
尽管存在挑战,Vibe Coding 的意义是革命性的:
- 编程民主化:不再需要 5-10 年的学习才能开发软件。
- 创新加速:想法到产品的距离被极大缩短。
- 入门门槛降低:可能成为传统软件开发的“入门毒品”。
正如 Karpathy 所说:“这将是软件开发的入门毒品。”当创造软件变得像说话一样简单时,我们将迎来一个全民编程的时代。
重塑数字基础设施:为 AI 代理铺路
既然 AI 代理正在成为新的数字信息消费者,我们需要为它们重新设计基础设施:
1. AI 友好的文档系统
就像网站有 robots.txt 指导爬虫一样,未来可能需要 llm.txt 来指导 LLM 理解网站功能。更重要的是,大量为人类设计的文档(充满截图和“点击这里”的指令)对 LLM 并不友好。
先进的公司已经开始行动:Vercel 和 Stripe 正在将文档转换为 Markdown 格式,用 curl 命令替换点击指令,让 LLM 能够直接理解和执行。
2. 数据转换工具
各种小工具正在涌现,帮助将传统数据转换为 LLM 友好的格式。比如 Gitingest 能将整个 GitHub 仓库转换为一个巨大的文本文件,方便 LLM 分析;DeepWiki 甚至能让 AI 自动分析代码库并生成文档。
虽然未来 LLM 可能会变得擅长操作人类界面,但 现在主动转换数据格式仍然是最经济高效的选择。
展望:软件的新纪元
Karpathy 的演讲为我们展现了一个激动人心的未来。我们正站在软件发展史的转折点上:
- 多范式并存:软件 1.0、2.0 和 3.0 将长期共存,优秀的工程师需要精通所有范式,并能根据具体需求做出最佳选择。
- 民主化的创新:当编程语言变成自然语言,创新的门槛被极大降低,更多人能够参与到数字世界的创造中。
- 渐进式自主:我们将在“自主性滑块”上逐步前进,见证软件如何变得越来越智能和自主。
技术扩散的“颠倒”现象
更有趣的是,LLM 技术的扩散方向被“颠倒”了:
- 传统模式:政府/企业 → 专业人士 → 普通消费者(如早期计算机用于军事弹道计算)
- LLM 模式:普通消费者(“如何煮鸡蛋”)→ 专业人士 → 企业/政府
这种自下而上的采用模式完全前所未有,可能会带来更多意想不到的创新。我们拥有了神奇的新计算机,却首先用它来帮助日常生活,而不是处理复杂的政府或军事任务。
正如 Karpathy 所说,现在是进入软件行业的 绝佳时机。我们需要重写大量代码,三种编程范式将并存,而 LLM 这些“易犯错的人类精神模拟器”为我们提供了前所未有的机遇。
在这个 Software 3.0 时代,我们的任务是学会与这些超人但有缺陷的助手协作,构建部分自治的应用,并逐步推动“自主性滑块”向右移动。重要的是,我们要避免过度兴奋,保持务实——这是软件,让我们认真对待。
欢迎长按下面的二维码关注 漫谈云原生 公众号,了解更多云原生和 AI 知识。
