滚动更新作为一个最佳实践,是每个服务在变更时都会采纳的方案。但在 Kubernetes 实践中,即便使用了滚动更新,也并不一定能够保证服务在更新和维护时总是可用的。
滚动更新的原理
在 Kubernetes 中,我们一般通过 Deployment、Daemonset 等控制器管理 Pod,并且把他们放到 Service 后面,使用 Service 的虚拟 IP 或者负载均衡器 IP 去访问。在 Pod 配置变更(如更新镜像)时,这些控制器默认就会采用滚动更新的方式逐步用新 Pod 替换已有的 Pod。下图所示就是一个典型的滚动更新[1]过程:
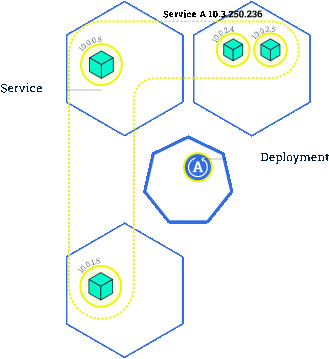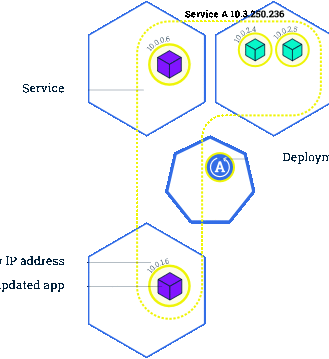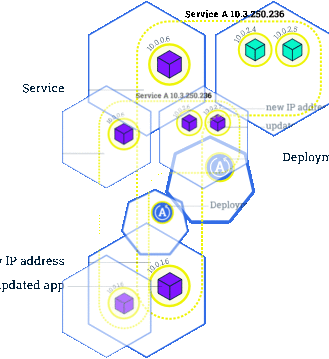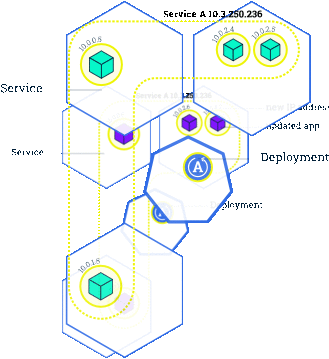
由于新的 Pod Ready 之后才会去删除旧的 Pod,在滚动更新中新的连接过来会自动路由到健康的 Pod 上,所以一般来说,新连接不会出问题,容易出问题的是旧连接。
这儿最容易想到的就是长连接。由于旧 Pod 最终会被删除,已有的长连接总是需要关闭。对这种长连接问题,想要解决,最好的方法是客户端在连接断开后重新建立连接。
而对短连接来说,是不是说就一定没问题呢?其实并不一定。
哪些问题会导致滚动更新时的服务中断
已有Pod过早终止
如果 Pod2 在终止的时候还有未处理完成的连接,那这些连接势必会失败。所以,在终止 Pod2 的时候,需要采用优雅关闭的方式,等待已有连接处理完成之后再终止。
比如,对 Nginx Pod 来说,可以这么做
lifecycle:
preStop:
exec:
command: [
# Gracefully shutdown nginx
"/usr/sbin/nginx", "-s", "quit"
]
新Pod未初始化完成就收到外部请求
很多容器启动时都有一个初始化的过程,虽然 Pod 处于 Running 状态了,但实际上进程还在初始化过程中,不能处理外部过来的请求。所以,在 Pod 启动过程中,需要一种机制,等着容器进程初始化完成之后再接收外部过来的请求。
这个问题比较好解决,Kubernetes 已经提供了 Readiness 探针,只需要应用提供一个探针接口即可。比如
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 10
httpGet:
port: 80
path: /
异步操作延迟导致iptables中没有健康Endpoint
滚动更新涉及到 kube-apiserver、kubelet、kube-controller-manager(包括 endpoint controller、service controller 和 cloud provider)以及 CNI 插件等。假设新建Pod的名字为Pod2,而旧的Pod名字为Pod1,这些组件在滚动更新过程中的典型过程如下图所示
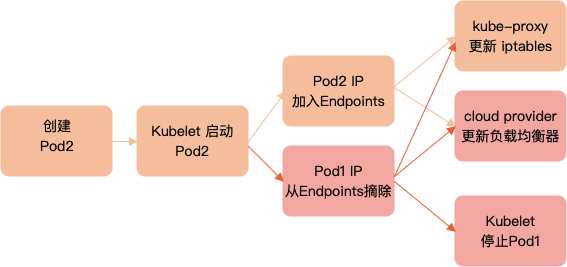
注意 Endpoints 更新(加入新 Pod2 IP 和删除旧 Pod1 IP)以及以后的步骤都是异步的。如果 Pod1 的 IP 摘除时间过早,Pod2 的 IP 还没有更新到 iptables 中,那么新的连接进来就会因为没有健康 Pod 而无法连接。
要解决这个问题不容易,但有一个简单的方法可以绕过去,即在 Zero Downtime Server Updates For Your Kubernetes Cluster[2] 中提到的利用 PreStop Hook 主动等一段时间之后再执行优雅关闭。
lifecycle:
preStop:
exec:
command: [
"sh", "-c",
# Introduce a delay to the shutdown sequence to wait for the
# pod eviction event to propagate. Then, gracefully shutdown
# nginx.
"sleep 15 && /usr/sbin/nginx -s quit",
]
集群维护导致所有Pod同时删除
在集群常规或者异常维护过程中,管理员经常需要驱逐一个或多个异常节点,把这些节点之上的 Pod 迁移到其他节点上面去。如果一个应用的所有 Pod 刚好在这些节点上,那就有可能所有 Pod 都被同时驱逐了,导致一段时间内没有任何健康的容器在运行。
Kubernetes 也为这个问题提供了一种很好的解决方法,即使用 PodDisruptionBudget[3] 给应用设置中断预算,避免所有 Pod 被同时重启。
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx
spec:
minAvailable: 1
selector:
matchLabels:
app: nginx
负载均衡器健康检测延迟
使用负载均衡器访问 Service 并且设置了 externalTrafficPolicy 为 Local(为了保留请求原始地址)时,除了上述提到的这些因素,负载均衡器本身提供的健康检测机制也可能会导致新连接短时间内的超时问题。
比如,在执行 kubectl drain node 的同时,对服务进行压力测试,就会发现部分连接断开(下面的例子成功率只有 97.27%):
Requests [total, rate, throughput] 299988, 4999.56, 4856.10
Duration [total, attack, wait] 1m0s, 1m0s, 87.815ms
Latencies [min, mean, 50, 90, 95, 99, max] 65.523ms, 866.673ms, 80.412ms, 2.409s, 5.066s, 10.003s, 10.367s
Bytes In [total, mean] 178585272, 595.31
Bytes Out [total, mean] 0, 0.00
Success [ratio] 97.27%
Status Codes [code:count] 0:8182 200:291806
Error Set:
context deadline exceeded (Client.Timeout or context cancellation while reading body)
这是为什么呢?
- 通常,负载均衡器后端放置的是所有的 Node,利用每个 Service 的 NodePort 来访问 Service。
- 当一个 Pod 被标记为 Terminating 状态时,Pod IP 会被 kube-controller-manager 立刻从 Endpoints 中摘除。
- 这之后,kube-proxy 就会把相应的 IP 从 iptables 中摘除掉,而负载均衡器此时还会继续把新请求发送到该 Pod 所在节点上。
- 由于 Pod IP 已经从 iptables 中清除了,新转发过来的请求就会失败。
对这个问题,一个最简单的方法就是把新的 Pod 调度到已有 Pod 所在节点上,确保 iptables 之后总是有健康的 Pod。
但这个方法不适用于节点驱逐的场景,毕竟节点驱逐之后不允许任何 Pod 继续运行了。所以,在节点驱逐的场景中,应该先从负载均衡器中把节点摘除,确保没有任何请求转发到节点之后,再去执行驱逐操作。
最佳实践
- 所有应用都使用控制器管理,并且必须多副本运行,尽量将副本分散到不同节点上。
- 为所有 Pod 添加 livenessProbe 和 readinessProbe。
- 容器进程在收到 SIGTERM 信号后优雅终止,比如持久化数据、清理网络连接等。
- 终止之前利用 preStop 稍等一会,等待各个组件异步操作完成。
- 必要时才设置 externalTrafficPolicy 为 Local,保留请求原始 IP。
- 使用 PodDiscruptionBudget 为应用设置中断预算,并总是使用 Eviction API(比如 kubectl drain)来清理 Pod,以确保遵循 PodDiscruptionBudget 的配置。
基于这些最佳实践,一个简单的 Nginx 配置就如下所示:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx
spec:
minAvailable: 1
selector:
matchLabels:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
...
template:
spec:
terminationGracePeriodSeconds: 30
containers:
- image: nginx
name: nginx
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 10
httpGet:
port: 80
path: /
lifecycle:
preStop:
exec:
command: [
"sh", "-c",
# Introduce a delay to the shutdown sequence to wait for the
# pod eviction event to propagate. Then, gracefully shutdown
# nginx.
"sleep 15 && /usr/sbin/nginx -s quit",
]
完整的 Nginx 示例以及压力测试步骤请参考 Kubernetes Handbook[4]。
参考资料
- [1] 滚动更新: https://kubernetes.io/docs/tutorials/kubernetes-basics/update/update-intro/
- [2] Zero Downtime Server Updates For Your Kubernetes Cluster: https://blog.gruntwork.io/zero-downtime-server-updates-for-your-kubernetes-cluster-902009df5b33
- [3] PodDisruptionBudget: https://kubernetes.io/docs/tasks/run-application/configure-pdb/
- [4] Kubernetes Handbook: https://github.com/feiskyer/kubernetes-handbook/tree/master/examples/nginx-ha
欢迎扫描下面的二维码关注 Feisky 公众号,回复任意关键字查询更多云原生知识库,或回复联系加我微信。
