本文整理自极客时间“10个问题带你全面理解Linux性能优化”直播,PPT下载请参考文末的 InfoQ 官方网站[1]。
1. 为什么面试官喜欢考察性能优化问题?
面试官考察性能优化问题的目的可能并不是要你设计一个性能很高的系统,而是为了全方位考察一个面试者的知识背景和实践能力。
- 性能优化涉及的知识面既需要深度,同时又需要一定的广度
•从深度上来说,考察一个面试者是不是有扎实的基础知识,比如操作系统原理、算法和数据结构等。•从广度上来说,考察一个面试者的架构能力,比如是否考虑过项目的架构设计、如何解决高可用和可扩展的问题、是不是碰到问题之后刨根问底、是不是系统掌握了项目中所采用的相关技术等。•性能优化是最能体现面试者综合能力的工作,既能考察各种常用技术,也能考察工程能力、思维能力、架构能力等等。
所以说,掌握了性能优化,实际上也代表着掌握了这些各方面的知识能力。
2. 性能优化知多少
•操作系统性能优化•算法性能优化•编程语言性能优化•编程框架性能优化•分布式系统性能优化•……
性能优化都是构建在操作系统、网络、算法、分布式系统等基础知识的大厦之上。只有深入掌握了这些基础知识,才能让你更好的掌握更高层次的技术,一通百通。
3. 怎么理解平均负载
平均负载就是平均活跃进程数,包括
•可运行状态进程 (R)•不可中断状态进程 (D)
平均负载的计算方法是活跃进程数的指数衰减平均值。
平均负载并不是看起来那么直观,所以又有了 Pressure Stall Information (PSI[2]):
•10s, 1m, 5m 硬件资源短缺的百分比•Kernel >= 4.20•通过 cgroup2 还可以查看每个进程的资源短缺情况
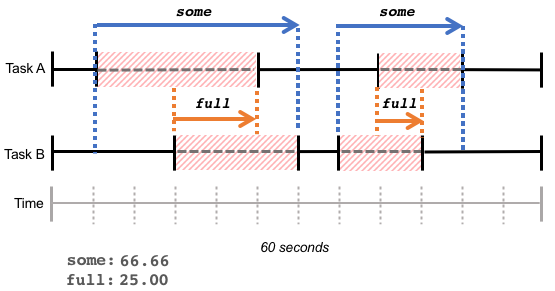
如下图所示,就是一个平均负载和 PSI 的对比关系:
4. 为什么内存池可以优化内存性能
虚拟内存空间
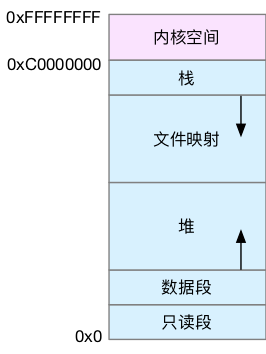
- 只读段,包括代码和常量等。
- 数据段,包括全局变量等。
- 堆,包括动态分配的内存,从低地址开始向上增长。
- 文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
- 栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。
在这五个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
- 对小块内存(小于 128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
- 而大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块空闲内存分配出去。
这两种方式,自然各有优缺点。
- brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率。
- 而 mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。
内存池解决了什么问题:
- 预分配内存
- 减少缺页异常
- 多线程保护
- 减少内存碎片
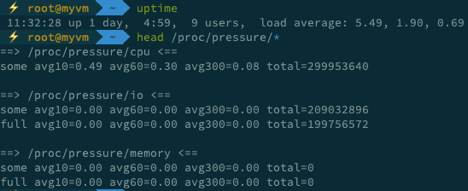
5. 怎么快速定位磁盘 I/O 性能问题
磁盘和文件系统 I/O 是最常见的一类性能问题,比如数据库性能、Redis 性能、网络存储的性能等都跟 I/O 性能有直接关系。要理解 I/O 性能,当然还得从基础的原理开始,比如下图所示的 I/O 栈:
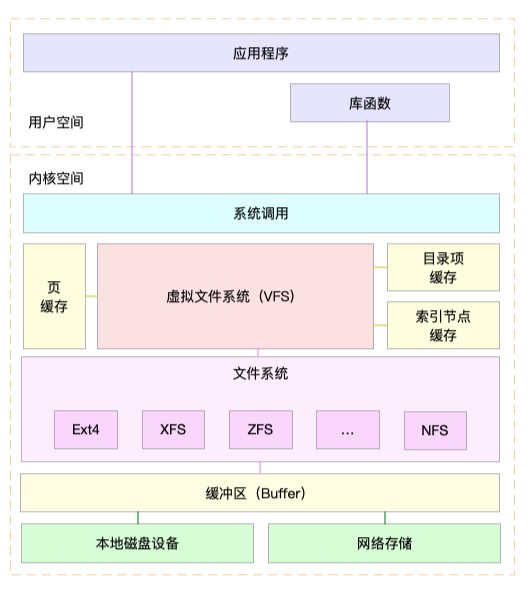
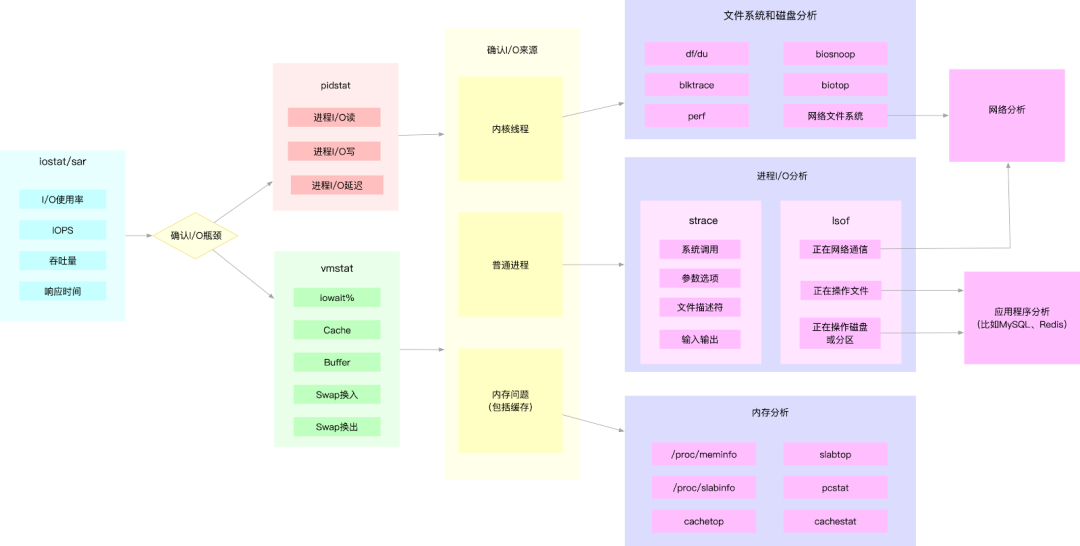
熟悉了原理,之后可以根据下图定位磁盘和文件系统 I/O 瓶颈
6. 为什么网络性能优化相对更难
网络性能优化相对更难的原因包括
•需要更深厚的基础知识:网络协议、内核协议栈、网络基础架构、网络编程接口以及分布式系统等。•需要更多的实践经验:既然涉及面广,网络性能问题的排查和优化就可能跟很多因素都有关,要快速找出瓶颈就需要更多的实践经验。
网络性能优化涉及面广,但也是构建分布式系统、微服务、云原生应用等必须要掌握的核心能力之一。在实际分析和优化网络性能时,可以按图索骥,根据 Linux 网络包内核协议栈处理路径和 Linux 通用 IP 网络栈的原理去逐步拆解分析。
下图是 Linux 网络包内核协议栈处理路径示意图:
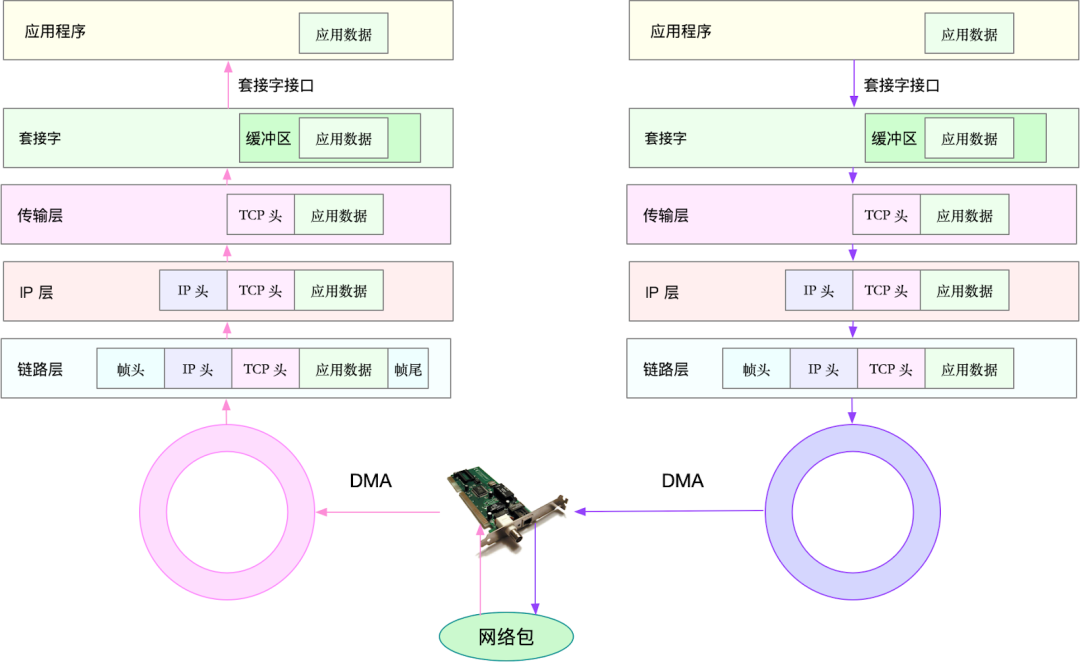
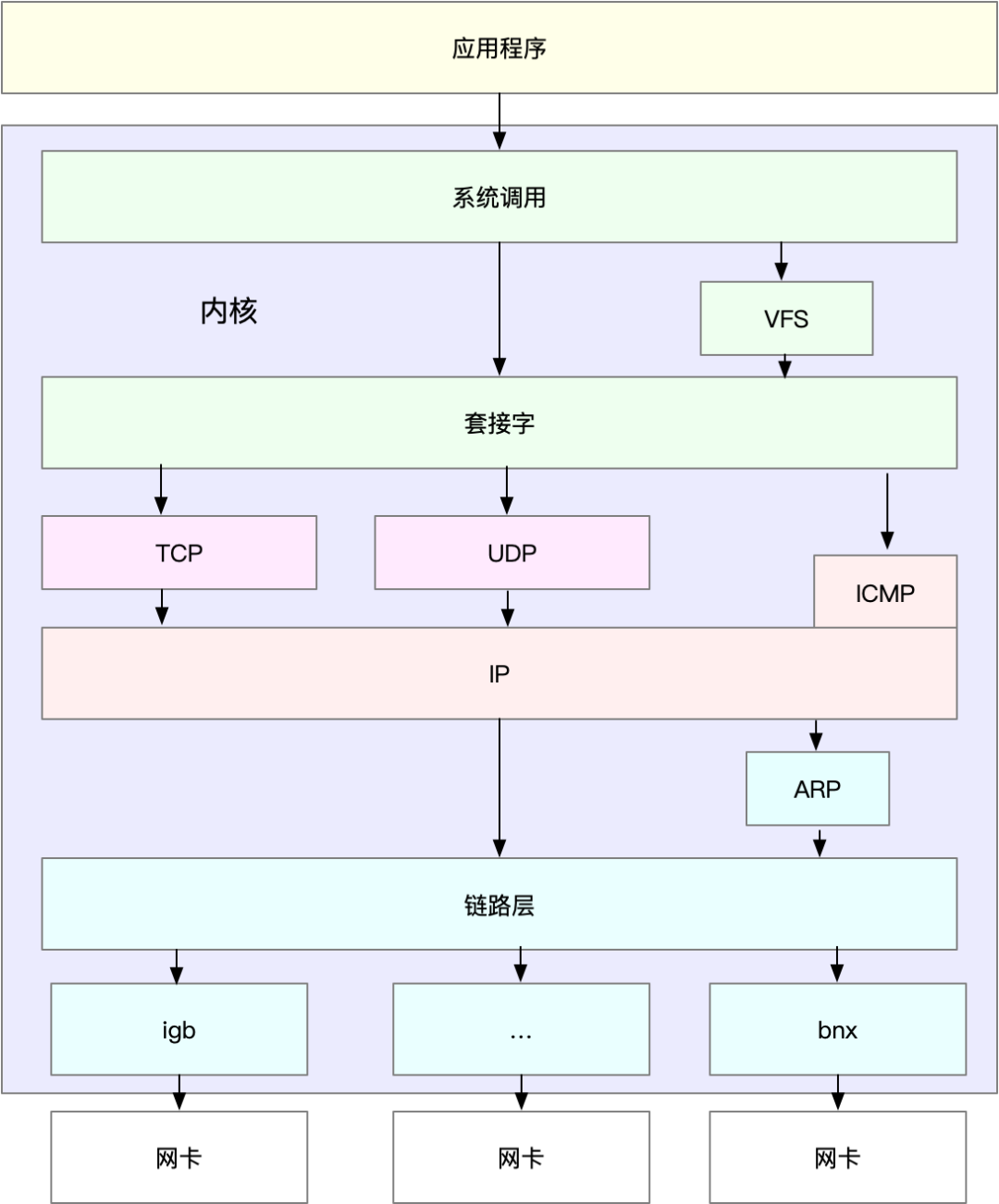
下图是 Linux 通用 IP 网络栈的示意图:
7. Linux 到底最大支持多少并发连接
要回答 Linux 到底最大支持多少并发连接,首先就要清楚 Linux 是通过什么方法来标识一个 “连接” 的。Linux 通过五元组来区分一个连接:协议、源 IP 地址、目的 IP 地址、源端口、目的端口。
对客户端来说,假设它要并发连接同一个服务,那就说明协议、源 IP 地址、目的 IP 地址和目的端口是固定的,唯一可变的是源端口。由于端口号是 16 位的,所以最大的并发连接数也就是 64K。
除此之外还有没有其他的限制的呢?实际上,端口号并不是唯一的限制,内核协议栈中还有很多东西限制最大的并发连接数:
•net.ipv4.ip_local_port_range 默认是从 32768 开始的•net.ipv4.tcp_fin_timeout 上一次的连接并不是立刻释放的,还需要等待一段时间才会释放
对服务器端来说,又是另一种情况。服务器主要是接受客户端请求,所以协议、目的 IP 地址和目的端口号是固定的,可变的就是客户端源 IP 地址和源端口号。这样,最大的并发连接数也就是可用 IP 地址数量 x 可用端口号数量,即 2^48(IPv6 还会更多)。
跟客户端类似,除了五元组之外,内核协议栈还有很多因素会影响最大连接数。比如最大文件描述符数量、内存、Sokect 缓存、连接跟踪等等。
8. 如何解决恼人的 TIME_WAIT 问题
既然 TIME_WAIT 很恼人,为什么说它还是必要的呢?这就要从 TCP 的工作原理说起了,下图是 TCP 状态图。我们知道 TCP 有两个最基本的机制:三次握手和四次挥手,TIME_WAIT 就是在四次挥手过程中必备的一个状态。
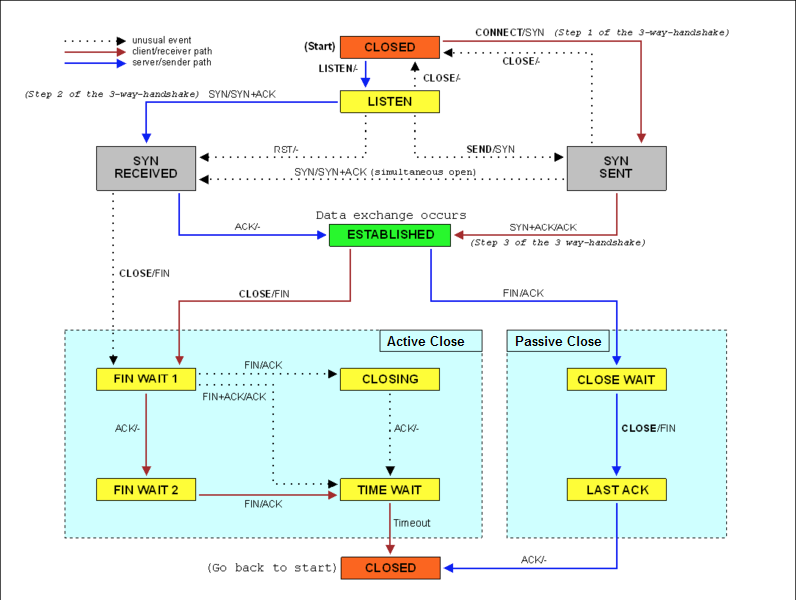
从 TCP 状态图中可以看到,主动关闭的一方会进入 TIME_WAIT 状态(而被动关闭的一方会进入 CLOSE_WAIT 状态)。TIME_WAIT 状态之所以存在是为了解决网络中的异常问题,比如
- 网络存在延迟和重传,前一个连接的延迟数据包可能被新的连接错误接收。
- 关闭连接时最后的 ACK 可能会丢失重传,这会干扰新的连接。
TIME_WAIT 连接数量多了以后,会导致三个危害:
- 占用内存
- •占用端口号
- 占用连接跟踪表
解决方法
- 增大 net.ipv4.tcp_max_tw_buckets 和 net.netfilter.nf_conntrack_max。
- 减小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,让系统尽快释放资源。
- 开启端口复用 net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中。
- 增大本地端口的范围 net.ipv4.ip_local_port_range 。
- 增加最大文件描述符的数量。你可以使用 fs.nr_open 和 fs.file-max。
9. 容器应用跟普通进程有什么不同
容器内的应用其实也是普通的 Linux 进程,只不过这些进程做了一些隔离:
•namespaces•cgroups•capabilities
namespace 隔离包括 pid, net, ipc, mnt, uts, user 等。
普通的 Linux 进程默认情况下的隔离通常较少,但也并非没有隔离。作为操作系统最基本的功能之一,内存管理会给每个进程分配不同的虚拟内存空间,也就是说进程的内存空间是隔离的。另外,以不同用户运行进程,所具备的权限也是不同的, root 用户拥有管理员权限,而普通用户运行的进程则没有。
当然,普通进程的这些隔离机制同样适用于容器应用。同理,容器应用的各种隔离机制也同样适用于普通进程,容器把这些额外的隔离机制封装成了更易用的接口。
10. 碰到问题不知所措怎么办
每个人都会碰到不知所措的问题,疑难杂症和灵异问题会伴随在每个技术人的成长过程中。所以不要慌,先梳理清楚问题再逐步攻破,
你可以从下面几个思路来解决这些难题:
•把握整体:先梳理清楚问题,搞清楚问题其实就成功了一大半。•系统监控:使用率、饱和度以及错误数这三类指标监控系统指标(USE法)。•应用监控 :延迟、请求数以及错误数这三类指标监控应用指标(RED法),配合链路跟踪可以更快定位问题。•动态追踪:跟内核或者应用当前状态有关的问题,利用动态追踪探入内核和进程内部分析现场,在很多疑难问题中都非常有效。
其实,性能问题并没有你想像得那么难,只要你理解了应用程序和系统的少数几个基本原理,再进行大量的实战练习,建立起整体性能的全局观,大多数性能问题的优化就会水到渠成。
更多性能优化的内容请参考极客时间专栏 Linux 性能优化实战[3]。
引用链接
[1]InfoQ 官方网站: https://ppt.infoq.cn/slide/show?cid=65&pid=2828[2]PSI: https://facebookmicrosites.github.io/psi[3]Linux 性能优化实战: https://time.geekbang.org/column/intro/140
欢迎扫描下面的二维码关注 Feisky 公众号,回复任意关键字查询更多云原生知识库,或回复联系加我微信。
