计算、存储和网络是云时代的三大基础服务,作为新一代基础架构的 Kubernetes 也不例外。而这三者之中,网络又是一个最难掌握和最容易出问题的服务。
网络模型
如果你去看 Kubernetes 的网络模型,其实它的网络模型很简单,只有下面简单的几条:
(1)IP-per-Pod,每个 Pod 都拥有一个独立 IP 地址,Pod 内所有容器共享一个网络命名空间
(2)集群内所有 Pod 都在一个直接连通的扁平网络中,可通过 IP 直接访问
(3)Service cluster IP 仅可在集群内部访问,外部请求需要通过 NodePort、LoadBalance 或者 Ingress 来访问
除此之外,Pod 的网络都是通过 CNI 网络插件和一系列的网络扩展来配置的,比如 Calico、Flannel 等网络插件,CoreDNS 扩展,Nginx ingress 控制器扩展,Ambassador API 网关,还有 Linkerd、Istio 等服务网格等。所有这些服务组合起来,构成了一个强大的容器网络,当然同时也增加了网络的复杂度。
服务发现
Kubernetes 网络原理中,最复杂的一块应该就是它的服务发现和负载均衡机制了。为了实现服务发现和负载均衡就需要一下几个组件协同:
1.用户通过 API 创建一个 Service2.kube-controller-manager 通过 Label 绑定 Pod 并创建同名 Endpoints 对象3.每个 Node 上面的 kube-proxy 为 Service 和 Endpoints 创建 iptables 规则,实现负载均衡和 DNAT
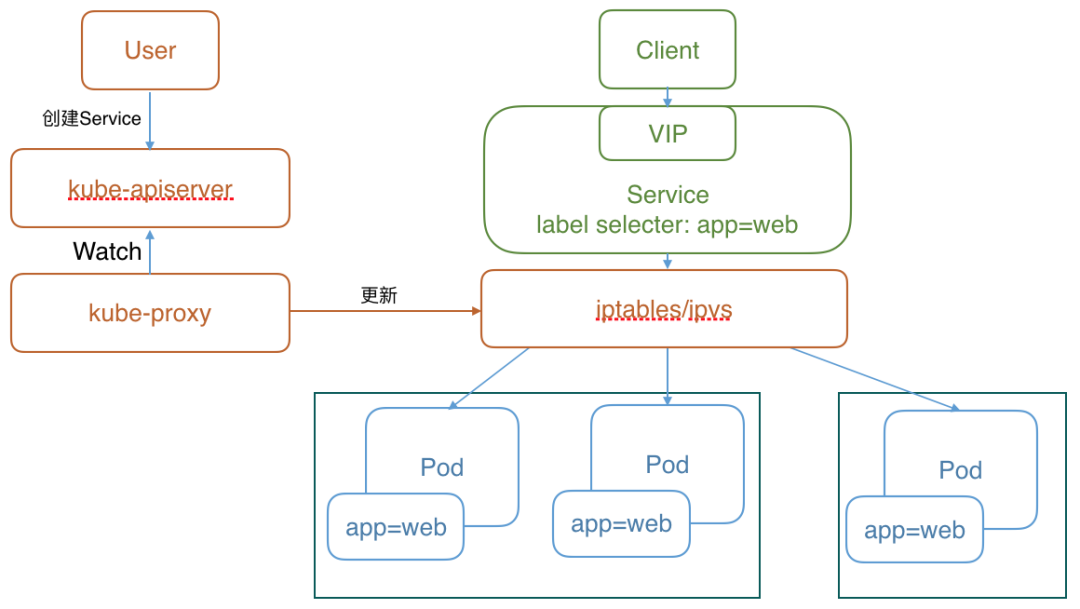
Kubernetes 网络中最核心的一块是 kube-proxy 如何实现了服务发现和负载均衡。默认 iptables 模式的工作流程如下图所示,掌握这个流程是理解 Kubernetes 网络的工作原理以及日常网络排错的关键。
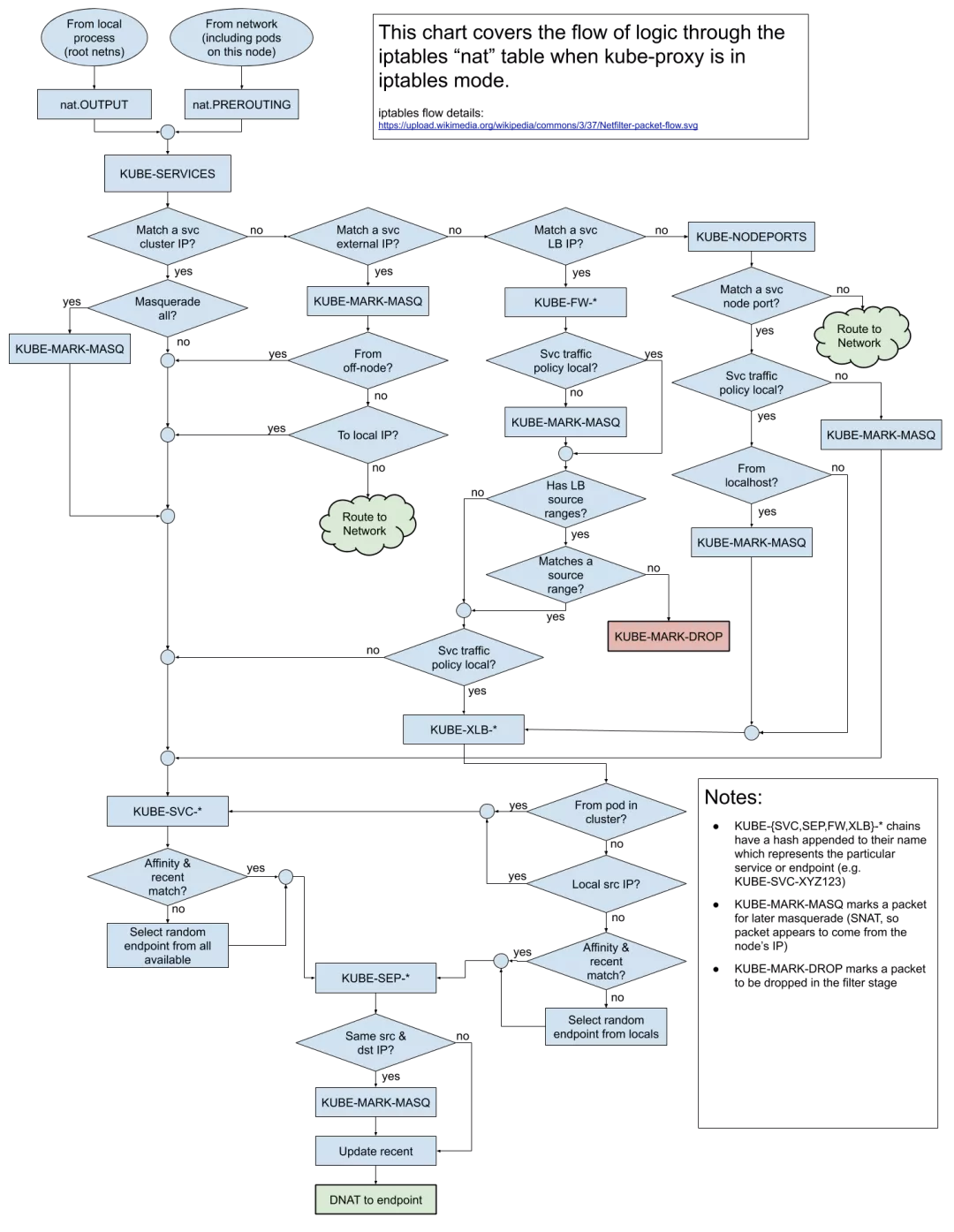
网络排错
网络是 Kubernetes 集群中最容器出问题的一个部分,由于涉及模块多,排查起来也通常比较困难。掌握网络排错是掌握 Kubernetes 最核心和最重要的一环。从整体上来看,说到 Kubernetes 的网络,其实无非就是以下三种情况之一
1.Pod 访问容器外部网络2.从容器外部访问 Pod 网络3.Pod 之间相互访问
排查网络问题基本上也是从这几种情况出发,定位出具体的网络异常点,再进而寻找解决方法。比如,一些常见的网络问题有
1.CNI 网络插件配置错误;2.Pod 网络路由丢失;3.Service 端口冲突、NetworkPolicy 策略配置错误;4.主机或云平台安全组、防火墙或安全策略阻止了容器网络。
详细的排错方法可以参考《Kubernetes指南》的网络排错部分。
针对实际的网络问题,Google Cloud 分享了一个 DNS 包丢失问题的排错案例,这个案例在 Kubernetes 集群 Day 2 运维中非常典型,基本上包含了网络故障发生之后最常用的一些网络排错步骤。详细的案例见 https://cloud.google.com/blog/topics/inside-google-cloud/google-cloud-support-engineer-solves-a-tough-dns-case。
容器网络的未来
从谷歌分享的网络排错案例中可以看到,即便是作为全球三大公有云平台之一,谷歌 TSE 也需要执行大量的工具和命令来逐步定位网络问题的根源。并且在很多时候,还需要客户自己来重现问题,才能拿到第一手的调试数据。
这一方面说明了网络问题的复杂性,另一方面也说明在网络排错、调试、监控等方面还有很多可以改进的空间。如果这些问题解决的出色,相应的网络方案很可能就会一跃而起,成为新的流行技术。
在这方面,Cilium 可以说是一个典型代表。Cilium 不仅需要较新的内核,还会通过 eBPF 机制在内核中注入包括观测、安全、过滤等在内的一系列网络机制。但这并没有阻止 Cilium 的流行。很多其他的网络方案也在借鉴 Cilium 的原理,借助 eBPF 加速网络性能,并实现更透明的网络观测机制。
如果你在网络性能和可观测性方面碰到瓶颈,不妨参考一下 Cilium 和 eBPF,它会给你带来意想不到的惊喜。
欢迎扫描下面的二维码关注 Feisky 公众号,回复任意关键字查询更多云原生知识库,或回复联系加我微信。
