{kind=link}
layout: post title: AWS S3故障回顾和总结 date: 2017-03-03 22:27:50 tags: [aws]
S3故障回顾
2月28日,AWS工程师在排查Northern Virginia (US-EAST-1) Region的一个S3计费问题时,因敲错了一条playbook的参数而误删了大量的s3控制服务引发了4小时的故障。这个误操作影响了两个S3的核心系统:
- Index系统,管理S3对象的元数据和位置,主要处理GET、LIST、PUT、DELETE请求
- Placement系统,管理新存储的分配和,主要处理PUT请求
由于S3的故障,一大批依赖于S3的AWS服务也发生故障(如EC2、EBS和Lambda等),进而也影响了近半的北美互联网服务。不过,这次故障只是影响了用户的访问,并没有丢失数据(可靠性还是保障的,S3有7个9的可靠性和4个9的可用性)。
虽然aws s3具有优秀的故障设计,在故障发生时一般会自动恢复。但是,由于s3极好的稳定性,Index和Placement系统已经多年未重启过了,这次重启重建index的时间超过预期,并且placement依赖于index系统,导致系统恢复花费了较长的时间。
改进措施
- 完善工具,保证即便有人操作错误也不会引发故障(对事不对人)
- 让删除操作缓慢些(以便有时间反悔)
- 加上一个最小资源数限制的SafeGuard
- 拆分现有的服务为更小单元(factoring services into cells),减小服务故障影响面,缩短服务的恢复时间
教训
- 高可用很难,不仅包括系统架构的高可用,更包括运维的高可用
- 跨Region和跨Availability Zone的重要性(比如Amazon和Netflix的服务并未受影响,因为它们在设计之初就处理了Region失效的问题),可以考虑的方案包括
- 跨Region的数据备份和恢复
- 跨Region的主从服务,包括Warm standby和Hot standby
- 跨Region的主主服务
- 故障恢复的重要性,充分保证Recovery Time Objective (RTO) and Recovery Point Objective (RPO)
- 自动化,人总是会犯错的,应该用技术而不是管理来解决问题(敏感操作放慢进程,以便有时间反悔)
- 故障和恢复演练,比如Google SRE指出他们有一个定期的服务停机计划,以验证系统是否真的符合预期
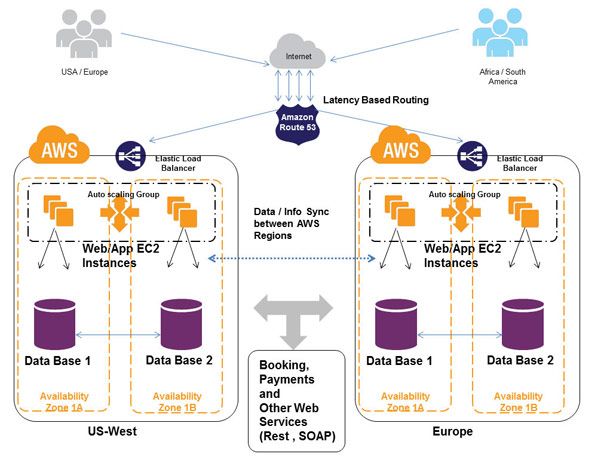
一个高可用系统的参考架构,图片来自The Learning AWS Blog