{kind=link}
OpenStack Magnum
http://www.csdn.net/article/2015-06-02/2824827
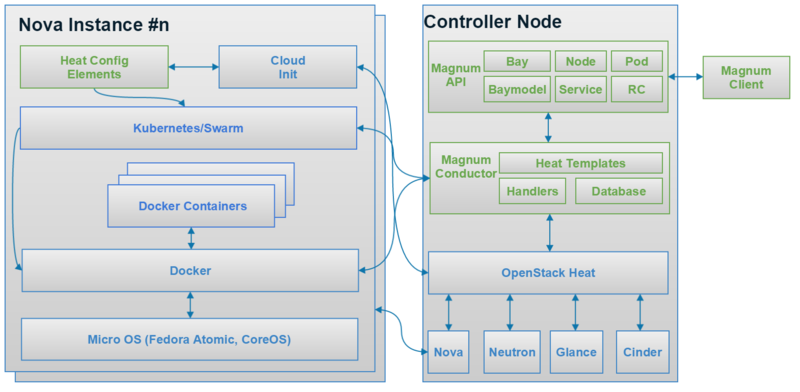
Magnum是去年巴黎峰会后开始的一个新项目,专门用来向用户提供容器服务,其最新的架构如图2所示。从去年11月份开始在StackForge提交第一个Patch,到今年3月份进入OpenStack Namespace,Magnum应该是OpenStack社区从StackForge迁移到OpenStack Namespace最快的一个项目。Magnum现在可以为用户提供Kubernetes as a Service和Swarm as a Service,大家应该会很快在L版看到Mesos as a Service。Magnum的一些Contributor,Adrian Otto是Rackspace的杰出工程师,Magnum和Solum的双重PTL;Steven Dake刚刚离开Redhat加入Cisco,他是Heat的创始人,现在Kolla的PTL,同时还在积极推动一个新项目Machine Learning as a Service;Davanum Srinivas (Dims)刚刚从IBM加入Mirantis,现在担任Oslo的PTL。关于他们的时间分配问题,Adrian的原话是会重点放在Magnum。
Magnum 6问6答
提问1:Magnum与Nova的区别? Magnum提供了一个用于管理应用容器的特制API。它们与Nova(机器)实例在生命周期和操作方面有着显著的不同。Magnum实际上是在使用Nova实例运行应用容器。
提问2:Magnum和Docker或者Kubernetes的区别? Magnum提供了一个可与Keystone和多租户部署兼容的异步API。它们不能在内部进行编排,而要借助于OpenStack编排系统。Magnum可将Kubernetes和Docker作为组件使用。
提问3:Magnum与Nova-Docker一样吗? 不一样。Nova-Docker是针对Nova的虚拟化驱动,允许容器被当做Nova实例创建。它们适用于当你需要将容器作为轻量化机器的场景。Magnum可以提供一些Nova API无法提供的容器功能,并且可以通过其自己的API实现一些与其他OpenStack服务相似的功能。由Magnum启动的容器可以在由Heat 创建的Nova实例上运行。
提问4:Magnum的用户是谁? Magnum的用户是OpenStack(公有或私有)云的运营人员。这些运营人员希望提供一个自助式的解决方案,以便将容器作为托管服务提供给他们的云用户。Magnum简化了与OpenStack的整合工作,让那些已经拥有Nova实例、Cinder卷和Trove数据库等资源的用户也可以创建应用容器,并提供比已有资源更多高级特性的运行环境。
创建IaaS资源的身份证书可以用来运行使用Magnum的容器化应用。适用于Magnum的一些高级功能可以将应用扩展到一定数量的实例当中。一旦出现故障,这些功能还可让你的应用自动重新生成一个实例。此外,与使用虚拟机相比,它们还可以更为紧密地将应用打包在一起。
提问5:如果我在Heat中使用Docker资源,是否可以获得相同的效果? 不可以。Docker Heat资源无法提供资源调度器,也无法对所用的容器技术进行选择。它们是专门针对Docker和使用Glance存储容器镜像所设计的。它们目前还没有分层镜像功能。如果分层镜像与本地缓存的基础镜像共同使用,那么这会导致启动容器的时间更长。Magnum利用了所有Docker在启动速度上的优势。
提问6:在Magnum中,多租户意味着什么(Magnum是否安全)? 由Magnum启动的容器、服务、Pod和Bay等资源仅能够被创建它们的租户使用者看到和访问。Bay不是共享的,这意味着容器无法作为附近租户在相同的内核上运行。这是一个关键的安全功能,它允许属于同一个租户的容器在相同的Pod和Bay中被打包,但是在不同租户之间各自运行独立的内核(在独立的Nova实例中)。这一点与使用无Magnum的Kubernetes系统不同,后者的设计初衷是仅供一个单租户环境,将安全隔离设计留给了系统实施者。在同一计算节点中运行属于不同租户的虚拟机时,Magnum可以提供与Nova同等水平的安全隔离。
从小往大的顺序的基本概念:
- Node:容器运行的节点,可以是裸机、虚拟机甚至容器。
- Bay:一组 Node 的集合(底层同一个驱动机制),是 Magnum 中容器调度的基本单元。Bay 在租户之间是隔离的。
- BayModle:类似于 Nova 中的 flavor,定义一个 Docker 集群的规格。
下面几个是来自 Kubernetes 中的概念。
- Container:容器。
- Pod:最小的管理单元,一个或多个相互关联的容器(一般运行相同应用),运行在同一个 Minion Node 上,共享同样的数据挂载和网络空间,代表某种应用的一个实例。
- Service:由一个或者多个 Pod 组成,代表一个抽象的应用服务,对外呈现为同一个访问接口,这样访问可以通过 service 来路由,而无需具体知道 pod 的地址。
- ReplicationController:对 pod 指定副本数,RC 可以保证一直存在该数目的副本存在并运行。
Hyper:基于Hypervisor的容器化解决方案
Hyper是前同事搞的一个可以在hypervisor上运行Docker镜像的引擎,它融合了Docker容器和虚拟机的优点,旨在打造一个性能更好、更安全的引擎。Hyper与Docker的核心区别在于Hyper没有使用Container技术,而是通过VM直接运行Docker镜像,它是一个完全基于虚拟化的解决方案。
王旭: Hypervisor的最明显的好处就在于,hypervisor的进程是由另一个kernel调度,系统调用由另一个kernel处理,而并非宿主机的kernel。这样,一方面用户可以选择自己的kernel,另一方面也增强了隔离性,hypervisor发生漏洞,对宿主机和其它虚拟机的威胁的概率是远低于容器漏洞的,毕竟容器向用户进程暴露了太多的入口点。
虚拟机的另一个优势是,虚拟机相关的产业链已经非常成熟,Xen/KVM已经有十多年的历史了,围绕虚拟机打造的OpenStack也有五年的历史了,和虚拟机有顺畅合作的软硬件上下游产品非常多,容器正在赶超,但虚拟机无疑是先行者。
王旭:我们把App-Centric的理念带回到虚机来,我们让虚机回到了它的原本使命——承载应用,而不是完全模拟物理机,承载完整的Linux发行版
hyper还搞了一个hyperstack的项目,通过magnum与openstack集成,值得期待。
http://server.zdnet.com.cn/server/2015/0608/3054676.shtml
tcptrace
https://fasterdata.es.net/performance-testing/network-troubleshooting-tools/tcpdump-tcptrace/
Tcpdump captures packets according to specific filters, while the tcptrace tool is used to analyze the data and output succinct summaries. Tcptrace will analyze a complete dump file (e.g. output the contents of the tcpdump into a file with the ‘-F’ option), and will categorize the output into distinct flow sumaries in the event that multiple exchanges exits. There are options to view the summaries, as well as produce files that can be viewed through the xplot viewer. The end goal is to identify the behavior of a specific flow for a given dump file, and be able to make judgements on the flow of the data and acknowledgements.
http://prefetch.net/blog/index.php/2006/04/17/debugging-tcp-connections-with-tcptrace/
tcptrace(1) operates on tcpdump and snoop binary files, and provides numerous statistics and connection details for each capture file passed as an argument. To get started with tcptrace(1), tcpdump(1) or snoop(1m) needs to be run to collect raw packet information. This information can be saved to a file with tcpdump(1)’s “-w” option, and complex filters can be applied to limit which hosts and ports data is collected from. $ tcpdump -i hme1 -w tcpdump.out -s 1520 port 80 $ tcptrace tcpdump.out 1 arg remaining, starting with ’tcpdump.out’ Ostermann’s tcptrace – version 6.2.0 – Fri Jul 26, 2002
44 packets seen, 44 TCP packets traced elapsed wallclock time: 0:00:00.025033, 1757 pkts/sec analyzed trace file elapsed time: 0:00:00.435121 TCP connection info: 1: c-24-98-83-96.hsd1.ga.comcast.net:63807 - prefetch.net:www (a2b) 7> 6< 2: c-24-98-83-96.hsd1.ga.comcast.net:62941 - prefetch.net:www (c2d) 6> 4< 3: c-24-98-83-96.hsd1.ga.comcast.net:57312 - prefetch.net:www (e2f) 6> 5< 4: c-24-98-83-96.hsd1.ga.comcast.net:55792 - prefetch.net:www (g2h) 6> 4<
WWDC swift 2.0
https://news.ycombinator.com/item?id=9680982
WWDC最大的亮点是swift 2.0要发布了,开源,并且支持Linux了,比较好奇swift在Linux上会怎么样,拭目以待吧。
青云雷击事件
2015年6月6日下午,因服务商“睿江科技”机房遭遇雷暴天气引发电力故障,青云广东1区全部硬件设备意外关机重启,造成青云官网及控制台短时无法访问、部署于GD1的用户业务暂时不可用。 与此同时,另一家云服务商LeanCloud也发生了长达4小时的服务中断情况。 Richard:机房遭遇雷击后,承载QingCloud设备所在区的两组UPS输出均出现了2秒钟的瞬时波动,从而导致了机柜出现瞬时断电再加电。UPS厂家给出的书面判断是,雷击楼体后,对UPS主机造成干扰,UPS浪涌保护器未生效,引起UPS并机线通信故障,电压回流造成电压高报警,逆变器过载关机,短时短路。
目前青云在全国共运行着8个区域,其中公有云的4个区是青云自营租用的,我们在每个省份都是选择当地最好 IDC 供应商,比如这次出问题的机房隶属广东睿江科技,这家 IDC 运营商在华南是绝对的领先者。这次事故机房是当地电信的枢纽机房,T3 等级,即便如此,也遇见了此次雷击引发电力闪断的巨大灾难。我们非常清楚云平台的服务能力一方面体现在软件技术实力,另一方面也取决于物理层面的稳定和可靠。我们已经下定决心自行投资运营数据中心,以将物理层面事故概率降到最低。需要强调的一点是,无论是云计算还是传统IT,都依赖于数据中心基础设施的稳定运行,而作为云服务商,我们的系统承载着众多用户的业务,因此要在数据中心的可靠性方面再下大力气。
来自InfoQ高效运维群的讨论主要观点如下:
- 机房整体崩溃的容灾切换方案和演练有必要加强。通讯基站都会做防雷,一个IDC不能因雷击就影响用户,雷击只是一个诱因。
- 现阶段国内云服务商还是以开发为主,并没有对网络、IDC、运维看的特别重要。
- 网络与IDC已成为运维的重要话题。运营商机房限制很多,多线融合是第三方IDC的优势,但网络是其瓶颈。
- 由于IDC互联成本太高,可以根据需求做DPN+DRaaS对部分或整个DC做实时异地容灾。但互联互通将成为趋势,也是市场发展的必然。
- 异地容灾的成本也不容小觑。目前看来,冷备有问题、双活有门槛,云服务商需要看自己的业务需要,看SLA。中断服务影响最大,所以稳定和高可用是架构设计第一要素。
- 做运维就是把更多的不可控变成可控。没做到高可用、实时异地容灾,设计上的单点故障也就难以解决。
- 现在的云产品只能谈可用性,还谈不上易用性。
http://www.infoq.com/cn/news/2015/06/QingCloud-IDC
基于Mesos和Docker的分布式计算平台
数人科技基于Mesos和Docker的分布式计算平台的实践,基于Mesos+Marathon,介绍了Mesos的集群管理、资源分配和任务调度、基于Zookeeper的服务发现、Graphite监控以及Ganglia监控。
http://www.csdn.net/article/2015-06-09/2824906 这周最热的就是Dockercon了,列表里面很多都是docker相关的。
Open Container Project (OCP)
Today we’re pleased to announce that CoreOS, Docker, and a large group of industry leaders are working together on a standard container format through the formation of the Open Container Project (OCP). OCP is housed under the Linux Foundation, and is chartered to establish common standards for software containers. This announcement means we are starting to see the concepts behind the App Container spec and Docker converge. This is a win for both users of containers and our industry at large.
https://coreos.com/blog/app-container-and-the-open-container-project/
Docker is donating draft specifications and code for container image format and runtime for the new project. Docker’s LibContainer project will become part of the new RunC project. CoreOS cofounder and chief executive Alex Polvi wrote in a blog post that he expects a good portion of its appc container specification to become part of the project, while his team will turn its rkt container runtime “into a leading container runtime around the new shared container format.”
runc https://github.com/opencontainers/runc
OCP http://www.opencontainers.org/
OCP spec https://github.com/opencontainers/specs 暂未公布,需要2-3周时间
Docker hackathon
一些有趣的项目包括:
- docker vlan implements the VLAN driver in libnetwork
- swarm-sec Swarm Security Assessment tool
- libsecurity A POC for using Docker to act on vulnerability releases in real time
- BenchRock 用来测试IaaS平台性能的工具
- sherdock Automatic GC of images based on regexp, Find and delete orphan Docker volumes
更多的项目见http://www.dockercon.com/hackathon
Docker experimental binary
Docker’s experimental binary gives you access to bleeding edge features that are not in, and may never make it into, Docker’s official release. An experimental build allows users to try out features early and give feedback to the Docker maintainers. In this way, we hope to refine our feature designs by exposing earlier to real-world usage.
In all cases, experimental features have gone through the same level of refining and quality control than any code that makes it into Docker: the difference is that the user interface and APIs may change.
Network and volume plugins are the very first experimental features introduced
Unlike the regular Docker binary, the experimental channels is built and updated nightly on https://experimental.docker.com. From one day to the next, new features may appear, while existing experimental features may be refined or entirely removed.
Each experimental feature is documented in a dedicated experimental section. This section explains the feature’s function and design goals. Because your feedback is essential to refine and decide on a feature’s future, you will also find links to GitHub issues where you can leave your comments, look for reported problems, or report on your experience.
http://blog.docker.com/2015/06/experimental-binary/
Docker plugins
The Docker plugins mechanism is now available in the new Docker experimental channel. Also available are the first Docker plugins, including Flocker for portable volumes across hosts, and networking plugins available from Weave, Project Calico, Nuage Networks, Cisco, VMware, Microsoft, and Midokura.
- Network plugins**, which allow third-party container networking solutions to connect containers to container networks, making it easier for containers to talk to each other even if they are running on different machines.
- Volume plugins**, which allow third-party container data management solutions to provide data volumes for containers which operate on data, such as databases, queues and key-value stores and other stateful applications that use the filesystem.
To demonstrate the value of plugins we are going to show you an example, that anyone can replicate themselves today. The example two plugins to enable container migration for an application on the Docker platform. We enhance an application with two extension points.
• Weave for portable networking, discovery, monitoring.
• Flocker for portable volumes and data.
• A Docker Swarm cluster runs the application described by Docker Compose
• We start a database on node 1, then later reschedule it on node 2, and it keeps its volumes and network identity!
• All of this is combined into one easy Docker experience via plugins.
See demo at https://plugins-demo-2015.github.io/
http://blog.docker.com/2015/06/extending-docker-with-plugins/
Disney docker deployment
Here are some of the components that are in use in the Disney environment:
- Chef: Chef handles the hosts and laying down the configuration for the Mesos master, the Marathon framework, the ZooKeeper endpoint configurations, etc. Chef also handles the initial setup of Consul and HAProxy.
- Docker: Docker is the packaging solution. Services are packaged using Docker. The Dockerfile for an application resides in the application repo. Application builds include building the Docker image and pushing it to the appropriate registry.
- Mesos: Mesos provides cluster scheduling, placing containers onto hosts. All interaction with Mesos comes through the frameworks (i.e., Marathon, spark, Cassandra, etc.).
- Marathon: The main framework in use is Marathon, which enables running Docker on Mesos. Marathon deployments (handled via JSON descriptions) will deploy Docker images and configure them appropriately (which image to use, which ports to expose, etc.). Health checks are also included in the Marathon deployment file. Marathon also allows Disney to define the upgrade strategy, which enables them to control how new images are deployed.
- Consul: Disney only uses the distributed key-value store functionality of Consul (not the service discovery aspect). Containers use consul-template to pull information from Consul to customize the configuration at run-time.
- HAProxy: HAProxy handles the routing of requests. Two health checks are involved: one on the HAProxy side, and one on the back-end service side. HAProxy is completely configured via Marathon’s service discovery mechanism.
- Jenkins: Jenkins handles the Docker build/push/deploy.
http://blog.scottlowe.org/2015/06/23/scaling-new-services/
Docker security
Docker能提供的安全保障将涵盖以下7点:
- namespace保障系统资源的隔离
- cgroup完成进程组资源的限制
- Linux的安全模块提供MAC(apparmor, SELinux)
- capabilities将root的权限细分为多种类型
- ulimit的功能更多维度的限制资源(docker 1.6之后支持)
- user namespace保障容器内部的root在host上并非root(预计docker 1.8支持)
- seccomp使得容器内进程受到系统调用权限的控制
Docker在安全方面还做了以下工作:
###降低镜像带来的安全风向
- 设置更为精简的Linux发行版:
- 移除不需要的package、用户以及二进制工具文件,
提出Tailored Profiles
- 容器可以创建least-privildge的文件
- 文件有能力随容器传递
- 通过独立的文件配置表明所有的权限
- 已经规划入runC
- 描述所有的隔离特性
Docker安全贡献的公司
- HuaWei在支持Docker的seccomp方面贡献有目共睹
- IBM大力贡献Docker的user namespace的支持
- Intel在Docker的bootchain方面投入效果可观
- RedHat则在SELinux方面的贡献受到社区的肯定
http://blog.daocloud.io/dockercon-day-2-security/
Project Orca
Project Orca has a vision of providing a top-to-bottom integrated stack that takes all the tools and plumbing (Docker Engine, Docker Swarm, Networking, GUI, Docker Compose, security, plus tools for installation, deployment, configuration, etc.). Project Orca fits into the “run” portion of the “build-ship-run” triangle on which Docker focuses.
The Orca demo starts out with a log in to a web-based UI. Hazlett shows how Orca integrates into directory services and provides role-based access controls, and shows the logging/auditing functionality, so that users can see what has happened. Orca will provide lists of images, as well as what’s inside the images (such as showing layers, and the sizes of layers). Orca has integration into Docker Swarm, to show the nodes in a Swarm cluster and manage the nodes in a Swarm cluster. Hazlett also shows how to see the images that are present in a cluster, pull updated images, and push them across the entire Swarm cluster. Naturally, Orca also shows the images that are running across the cluster, the images used by each container, and display the details for running containers (the node on which it’s running, the ports that are exposed, the resources that are in use, the volumes associated with the container). Viewing the logs from a Docker container is also readily accessible from within Orca, as is real-time streaming statistics for the containers. Orca introduces the idea of “stacks,” which correspond to a Docker Compose configuration (sounds a lot like OpenStack Heat to me). Deploying a stack is like docker-compose up, and application-specific (stack-specific) metrics are available within Orca. Orca also integrates the ability to scale the number of containers associated with a stack. Developers can update their application definitions (via changes to the Compose YAML definition), and Orca will allow those changes to be dynamically deployed to production without adverse affect to operations’ ability to scale up or scale down capacity.
http://blog.scottlowe.org/2015/06/23/dockercon-day2-general-session/
http://blog.daocloud.io/dockercon-day-2-production-readiness/
Project Bonneville
Bonneville is a Docker daemon with custom VMware graph, execution and network drivers that delivers a fully-compatible API to vanilla Docker clients. The pure approach Bonneville takes is that the container is a VM, and the VM is a container. There is no distinction, no encapsulation, and no in-guest virtualization. All of the necessary container infrastructure is outside of the VM in the container host. The container is an x86 hardware virtualized VM – nothing more, nothing less.
http://blogs.vmware.com/cloudnative/introducing-project-bonneville
http://venturebeat.com/2015/06/22/everything-announced-at-dockercon-2015/