{kind=link}
Shanghai,
CN-31
相比Docker一个二进制文件解决所有问题,Kubernetes则为不同的服务提供了不同的二进制文件,并将一些服务放到了addons中。故而,Kubernetes的部署相对要麻烦的多。借助minikube项目,现在可以很方便的在本机快速启动一个单节点的Kubernetes集群。
... ➦Flannel is a virtual network that gives a subnet to each host for use with container runtimes.
Platforms like Google’s Kubernetes assume that each container (pod) has a unique, routable IP inside the cluster. The advantage of this model is that it reduces the complexity of doing port mapping.
flannel runs an agent, flanneld, on each host and is responsible for allocating a subnet lease out of a preconfigured address space. flannel uses etcd to store the network configuration, allocated subnets, and auxiliary data (such as host’s IP). The forwarding of packets is achieved using one of several strategies that are known as backends. The simplest backend is udp and uses a TUN device to encapsulate every IP fragment in a UDP packet, forming an overlay network. The following diagram demonstrates the path a packet takes as it traverses the overlay network:
... ➦[TOC]
Docker v1.12 brings in its integrated orchestration into docker engine.
... ➦Starting with Docker 1.12, we have added features to the core Docker Engine to make multi-host and multi-container orchestration easy. We’ve added new API objects, like Service and Node, that will let you use the Docker API to deploy and manage apps on a group of Docker Engines called a swarm. With Docker 1.12, the best way to orchestrate Docker is Docker!
Table of contents:
[TOC]
The latest master branch of runV has already supported running as an runtime in docker. Since v1.11, docker introduced OCI contain runtime (runc) integration via containerd. Since runc and runV are both recommended implementation of OCI, it is natural to make runV working with containerd.
Now let’s have a try.
Docker could be installed via https://docs.docker.com/engine/installation/.
Since only master branch of runV supports running integrated with docker, we should compile runV by source.
... ➦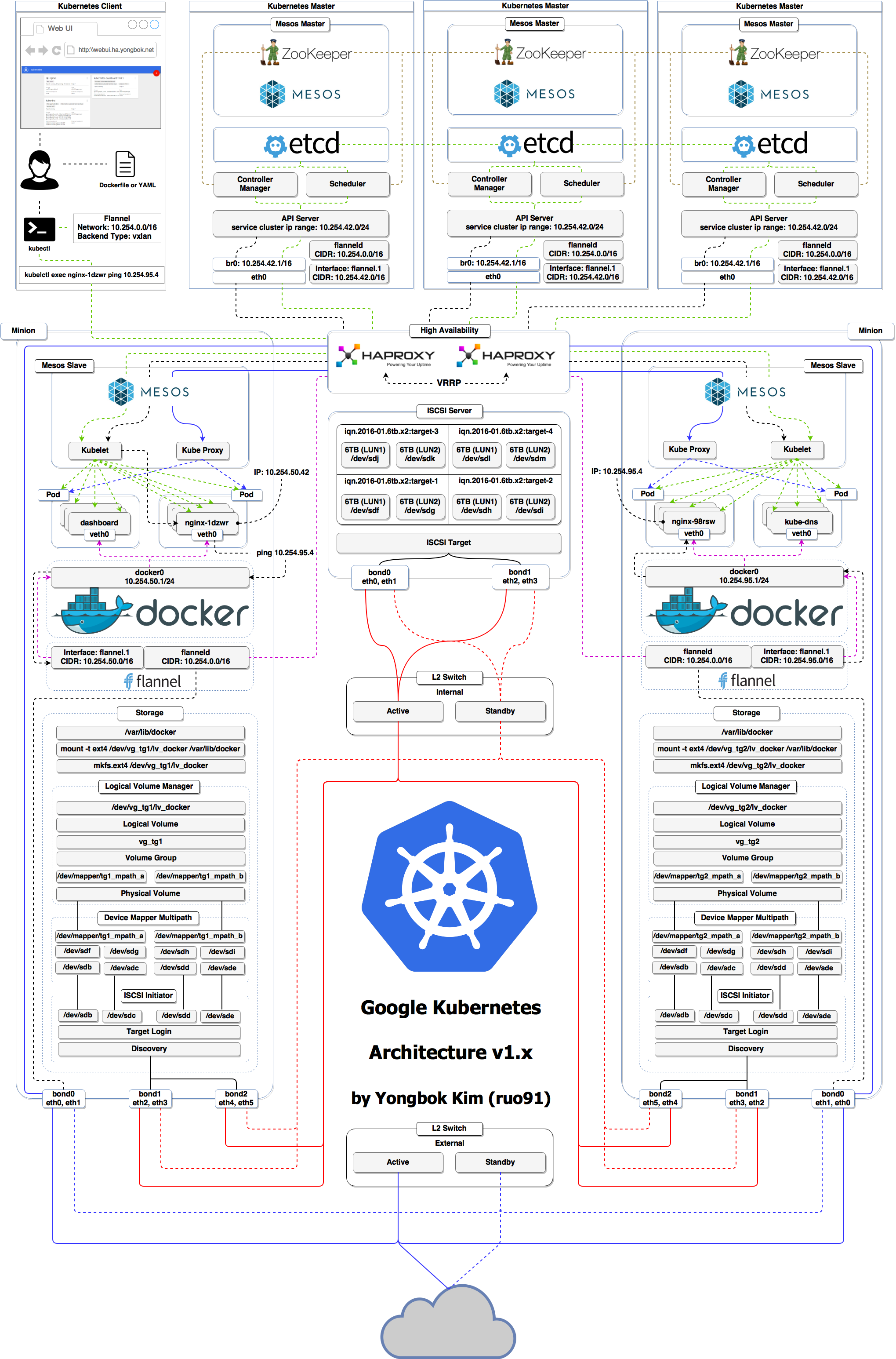
From http://cdn.yongbok.net/ruo91/architecture/k8s/kubernetes_mesos_architecture_v1.x.png
Notes: this post is copied from http://blog.kubernetes.io/2016/05/hypernetes-security-and-multi-tenancy-in-kubernetes.html.
Today’s guest post is written by Harry Zhang and Pengfei Ni, engineers at HyperHQ, describing a new hypervisor based container called HyperContainer
While many developers and security professionals are comfortable with Linux containers as an effective boundary, many users need a stronger degree of isolation, particularly for those running in a multi-tenant environment. Sadly, today, those users are forced to run their containers inside virtual machines, even one VM per container.
... ➦Docker 1.11 has moved to runc with containerd, I am interested in how it processing shared netns accross containers.
For example, I have already running a container 75599a6f387b7842c6da57efd38f9742b2ca621782f891402f83852c66dbd706. A new container within same netns can be created with cmd:
docker run -itd --net=container:75599a6f387b alpine sh
This will generate a runc config.json as follows:
{
"ociVersion": "0.6.0-dev",
"platform": {
"os": "linux",
"arch": "amd64"
},
"process": {
"terminal": true,
"user": {
"additionalGids": [
0,
1,
2,
3,
4,
6,
10,
11,
20,
26,
27
]
},
"args": [
"sh"
],
"env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"HOSTNAME=75599a6f387b",
"TERM=xterm"
],
"cwd": "/",
"capabilities": [
"CAP_CHOWN",
"CAP_DAC_OVERRIDE",
"CAP_FSETID",
"CAP_FOWNER",
"CAP_MKNOD",
"CAP_NET_RAW",
"CAP_SETGID",
"CAP_SETUID",
"CAP_SETFCAP",
"CAP_SETPCAP",
"CAP_NET_BIND_SERVICE",
"CAP_SYS_CHROOT",
"CAP_KILL",
"CAP_AUDIT_WRITE"
]
},
"root": {
"path": "/var/lib/docker/devicemapper/mnt/d33c7932917e64bde482b437fc3ccaad9a00a04e0cf49e39f9d3be5d71991db6/rootfs",
"readonly": false
},
"hostname": "75599a6f387b",
"mounts": [
{
"destination": "/proc",
"type": "proc",
"source": "proc",
"options": [
"nosuid",
"noexec",
"nodev"
]
},
{
"destination": "/dev",
"type": "tmpfs",
"source": "tmpfs",
"options": [
"nosuid",
"strictatime",
"mode=755"
]
},
{
"destination": "/dev/pts",
"type": "devpts",
"source": "devpts",
"options": [
"nosuid",
"noexec",
"newinstance",
"ptmxmode=0666",
"mode=0620",
"gid=5"
]
},
{
"destination": "/sys",
"type": "sysfs",
"source": "sysfs",
"options": [
"nosuid",
"noexec",
"nodev",
"ro"
]
},
{
"destination": "/sys/fs/cgroup",
"type": "cgroup",
"source": "cgroup",
"options": [
"ro",
"nosuid",
"noexec",
"nodev"
]
},
{
"destination": "/dev/mqueue",
"type": "mqueue",
"source": "mqueue",
"options": [
"nosuid",
"noexec",
"nodev"
]
},
{
"destination": "/etc/resolv.conf",
"type": "bind",
"source": "/var/lib/docker/containers/75599a6f387b7842c6da57efd38f9742b2ca621782f891402f83852c66dbd706/resolv.conf",
"options": [
"rbind",
"rprivate"
]
},
{
"destination": "/etc/hostname",
"type": "bind",
"source": "/var/lib/docker/containers/75599a6f387b7842c6da57efd38f9742b2ca621782f891402f83852c66dbd706/hostname",
"options": [
"rbind",
"rprivate"
]
},
{
"destination": "/etc/hosts",
"type": "bind",
"source": "/var/lib/docker/containers/75599a6f387b7842c6da57efd38f9742b2ca621782f891402f83852c66dbd706/hosts",
"options": [
"rbind",
"rprivate"
]
},
{
"destination": "/dev/shm",
"type": "bind",
"source": "/var/lib/docker/containers/d8230e57e88d15515a94138ef512a4271e31d03bb6fb257b3d57a847e70b5c68/shm",
"options": [
"rbind",
"rprivate"
]
}
],
"hooks": {},
"linux": {
"resources": {
"devices": [
{
"allow": false,
"access": "rwm"
},
{
"allow": true,
"type": "c",
"major": 1,
"minor": 5,
"access": "rwm"
},
{
"allow": true,
"type": "c",
"major": 1,
"minor": 3,
"access": "rwm"
},
{
"allow": true,
"type": "c",
"major": 1,
"minor": 9,
"access": "rwm"
},
{
"allow": true,
"type": "c",
"major": 1,
"minor": 8,
"access": "rwm"
},
{
"allow": true,
"type": "c",
"major": 5,
"minor": 0,
"access": "rwm"
},
{
"allow": true,
"type": "c",
"major": 5,
"minor": 1,
"access": "rwm"
},
{
"allow": false,
"type": "c",
"major": 10,
"minor": 229,
"access": "rwm"
}
],
"disableOOMKiller": false,
"oomScoreAdj": 0,
"memory": {
"kernelTCP": null,
"swappiness": 18446744073709551615
},
"cpu": {},
"pids": {
"limit": 0
},
"blockIO": {
"blkioWeight": 0
}
},
"cgroupsPath": "/docker/d8230e57e88d15515a94138ef512a4271e31d03bb6fb257b3d57a847e70b5c68",
"namespaces": [
{
"type": "mount"
},
{
"type": "network",
"path": "/proc/14702/ns/net"
},
{
"type": "uts"
},
{
"type": "pid"
},
{
"type": "ipc"
}
],
"devices": [
{
"path": "/dev/zero",
"type": "c",
"major": 1,
"minor": 5,
"fileMode": 438,
"uid": 0,
"gid": 0
},
{
"path": "/dev/null",
"type": "c",
"major": 1,
"minor": 3,
"fileMode": 438,
"uid": 0,
"gid": 0
},
{
"path": "/dev/urandom",
"type": "c",
"major": 1,
"minor": 9,
"fileMode": 438,
"uid": 0,
"gid": 0
},
{
"path": "/dev/random",
"type": "c",
"major": 1,
"minor": 8,
"fileMode": 438,
"uid": 0,
"gid": 0
},
{
"path": "/dev/fuse",
"type": "c",
"major": 10,
"minor": 229,
"fileMode": 438,
"uid": 0,
"gid": 0
}
],
"maskedPaths": [
"/proc/kcore",
"/proc/latency_stats",
"/proc/timer_stats",
"/proc/sched_debug"
],
"readonlyPaths": [
"/proc/asound",
"/proc/bus",
"/proc/fs",
"/proc/irq",
"/proc/sys",
"/proc/sysrq-trigger"
]
}
}
So, it is very clear how it works:
... ➦package main
import (
"fmt"
"unsafe"
)
func str2bytes(s string) []byte {
ptr := (*[2]uintptr)(unsafe.Pointer(&s))
btr := [3]uintptr{ptr[0], ptr[1], ptr[1]}
return *(*[]byte)(unsafe.Pointer(&btr))
}
func bytes2str(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
func main() {
s := "abcdefghi"
b := str2bytes(s)
s2 := bytes2str(b)
fmt.Println(s, b, s2)
}
Go Proverbs: A little copying is better than a little dependency. 对于一些短小的对象,复制成本远小于在堆上分配和回收操作。
{% pdf http://feiskyer.github.io/assets/ccs.pdf %}
SIG-Networking: Kubernetes Network Policy APIs Coming in 1.3
... ➦One problem many users have is that the open access network policy of Kubernetes is not suitable for applications that need more precise control over the traffic that accesses a pod or service. Today, this could be a multi-tier application where traffic is only allowed from a tier’s neighbor. But as new Cloud Native applications are built by composing microservices, the ability to control traffic as it flows among these services becomes even more critical.
{kind=link}